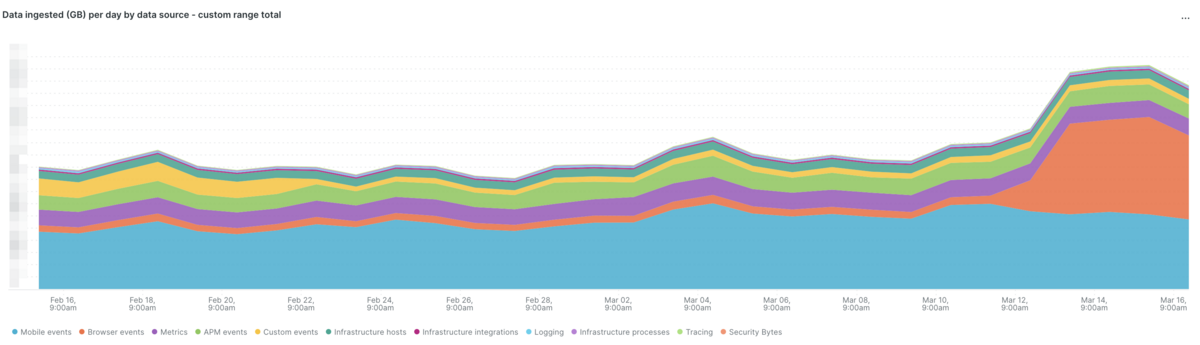
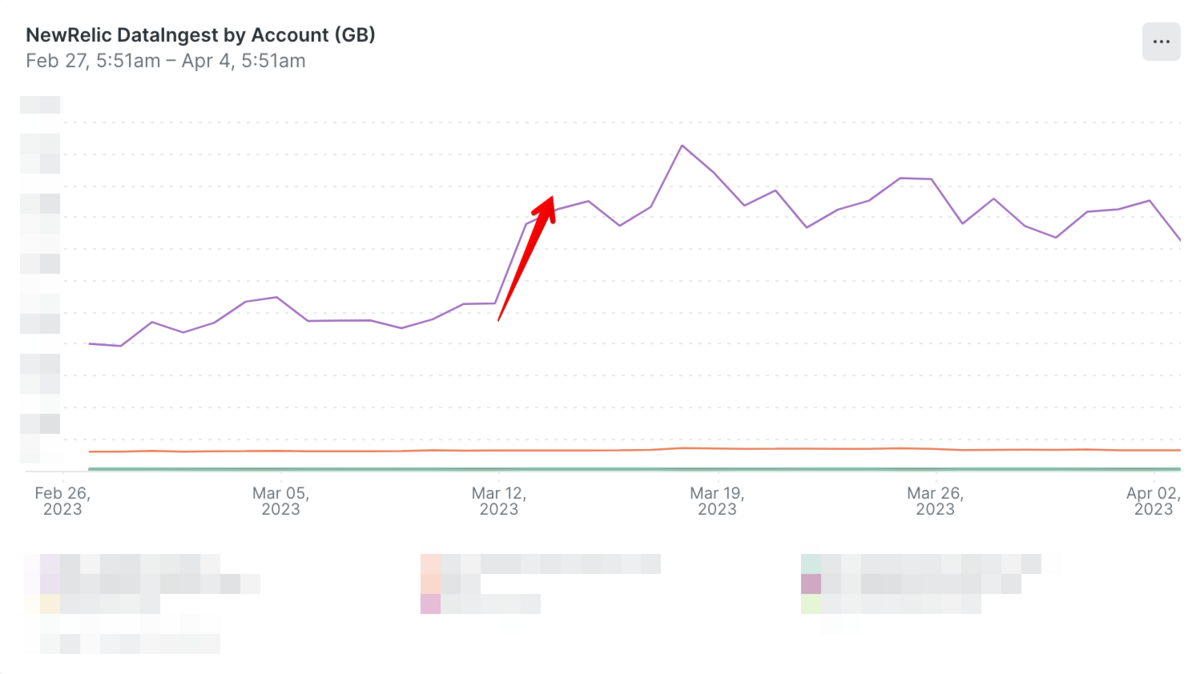
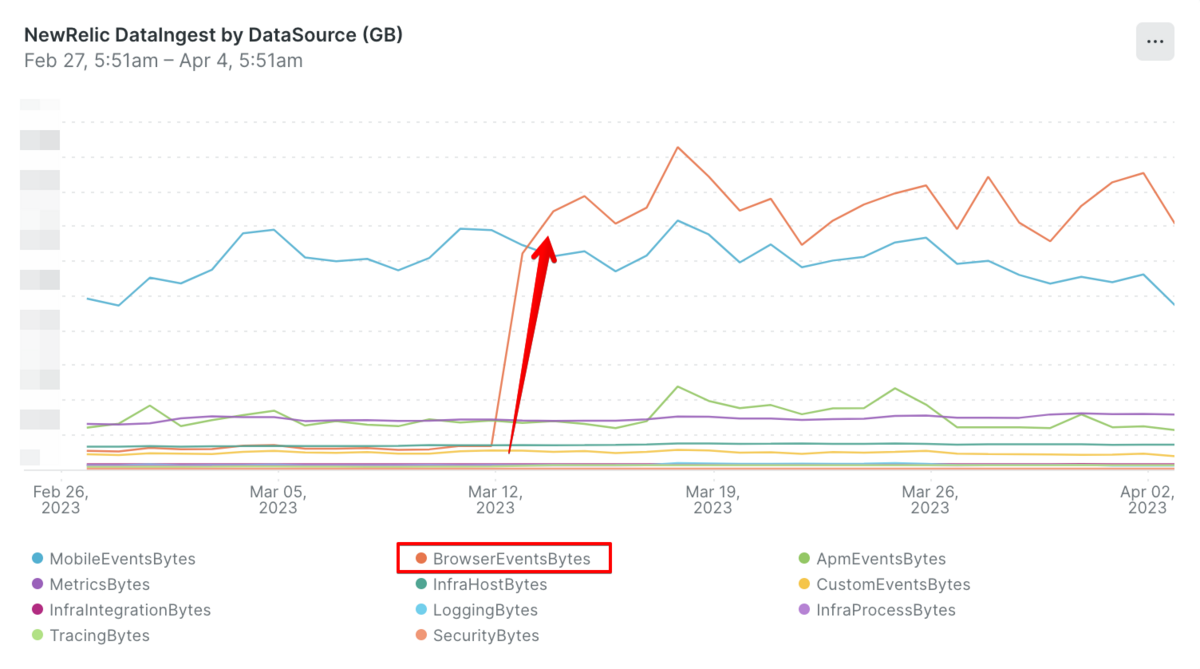
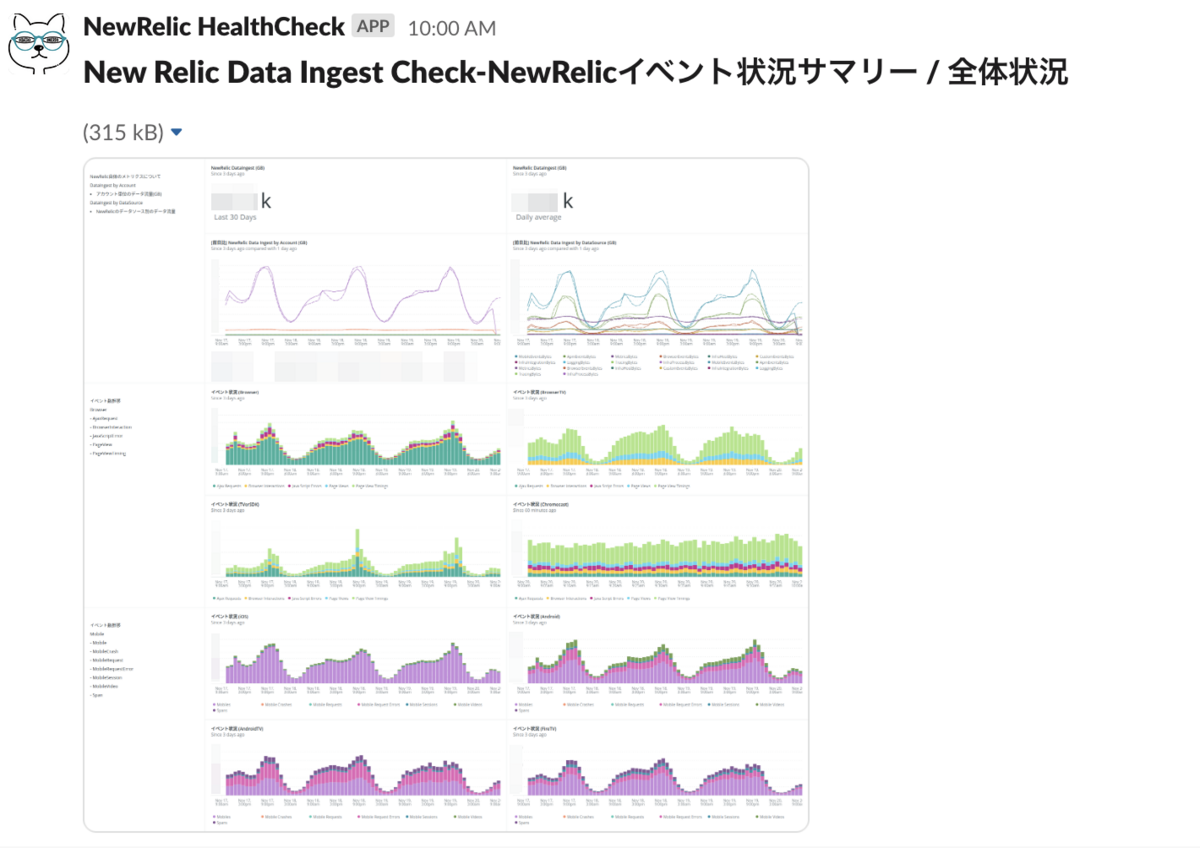
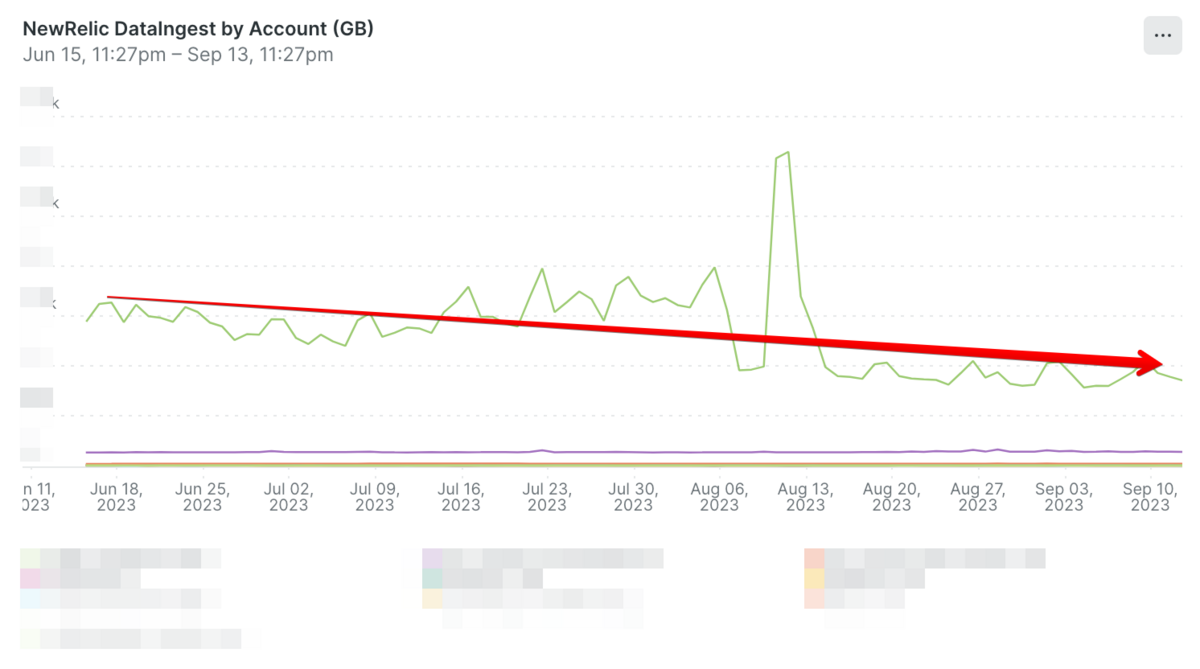
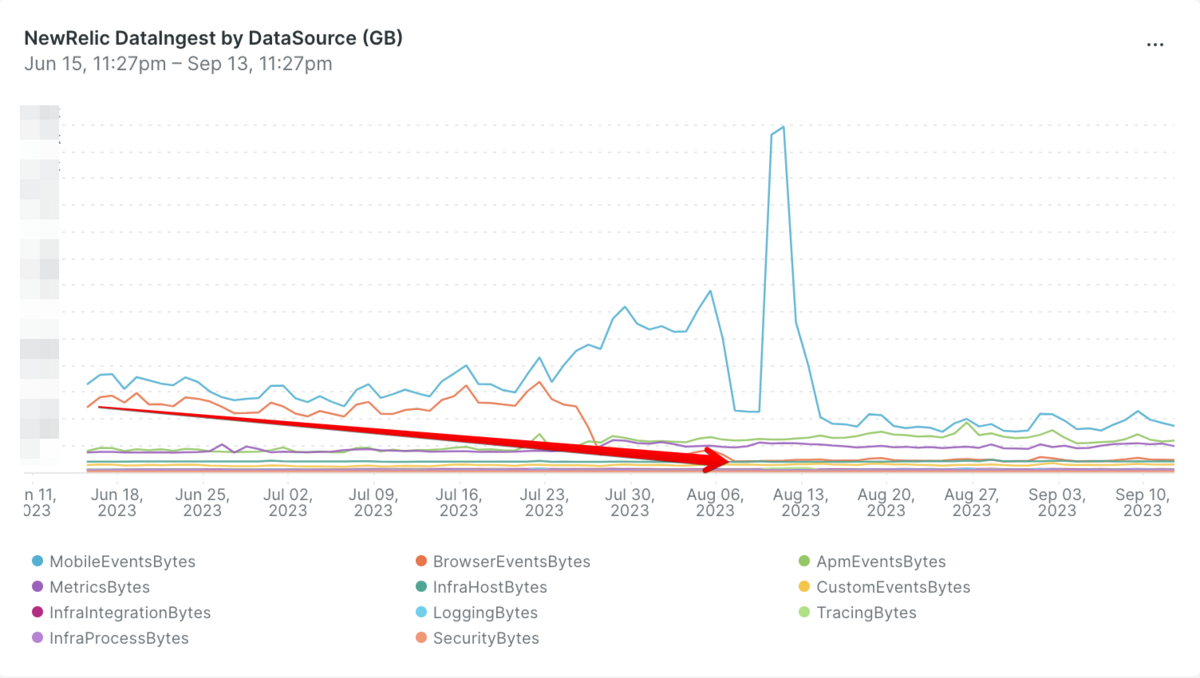
New Relicのサポートにもアップデート内容の確認や原因の調査についてご相談したのですが、残念ながらこれという決定的な証拠を見つけることができませんでした。可能性としては「当初の設定の不備により必要なデータを取得できていなかった」もしくは「分散トレーシング周りのアップデートがあり取得できるイベントが増えた」かと考えています。
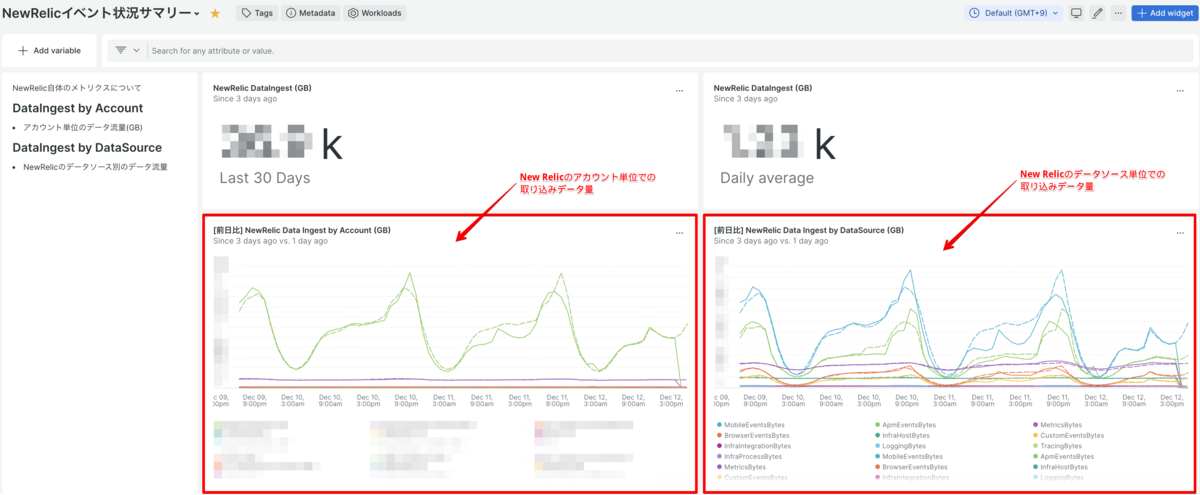
# [前日比] アカウント別のデータ量
SELECT rate(sum(GigabytesIngested), 1 day) AS avgGbIngestTimeseriesByAccount FROM NrConsumption WHERE productLine = 'DataPlatform' FACET consumingAccountName TIMESERIES AUTO SINCE 3 days AGO COMPARE WITH 1 day ago
# [前日比] データソース別のデータ量
SELECT rate(sum(GigabytesIngested), 1 day) AS avgGbIngestTimeseries FROM NrConsumption WHERE productLine = 'DataPlatform' FACET usageMetric LIMIT MAX TIMESERIES AUTO SINCE 3 days AGO COMPARE WITH 1 day ago
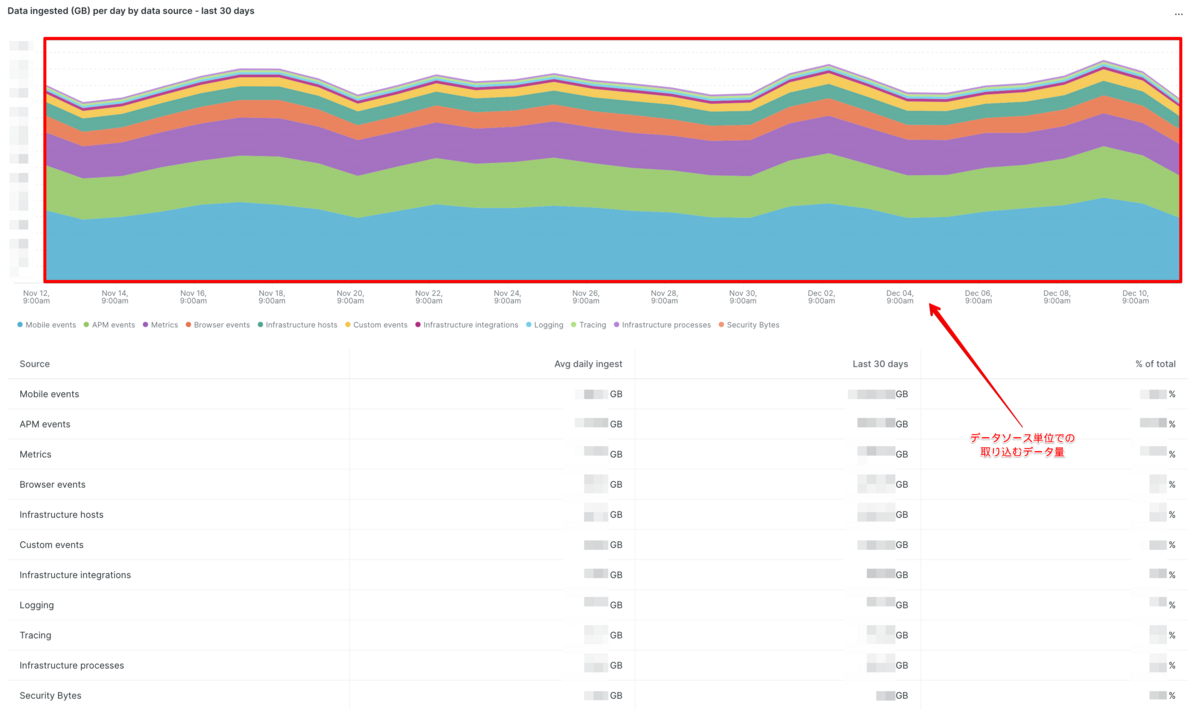
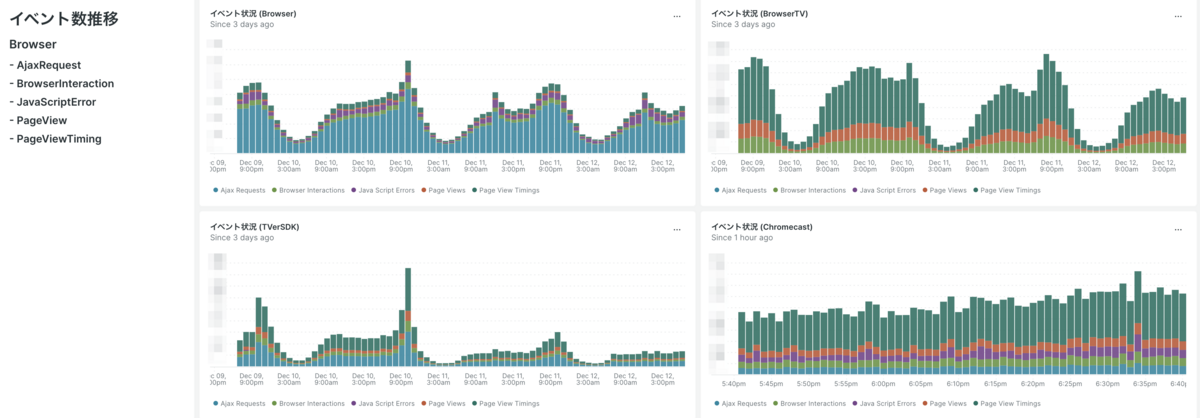
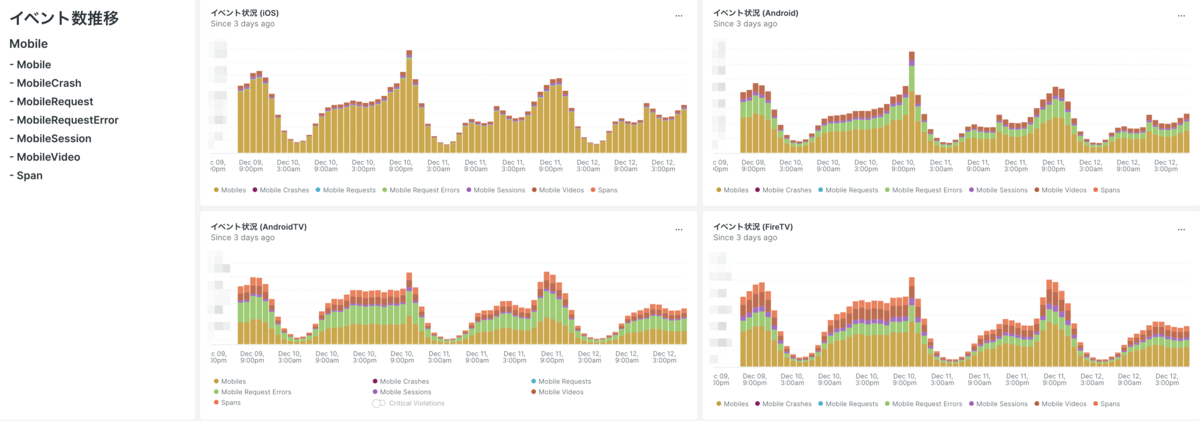
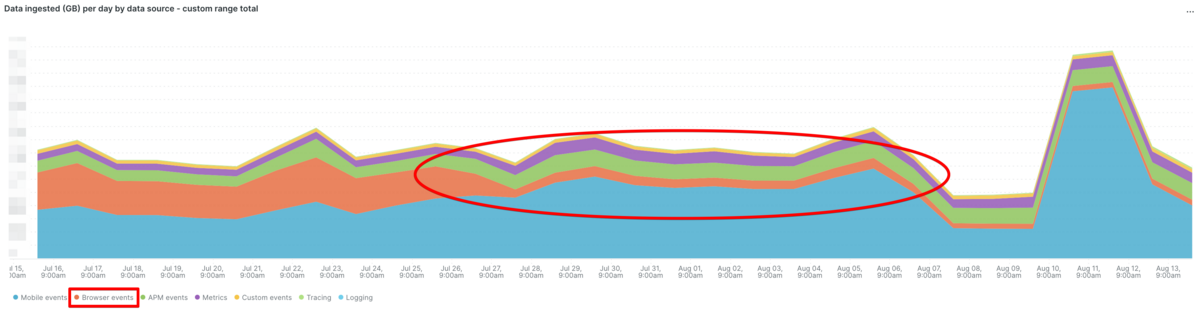
また、バックエンド (New Relic APM, New Relic Infrastructure) に比べるとフロントエンド (New Relic Browser, New Relic Mobile) の方がデータ量にばらつきが大きいことがわかっているため、主要なイベント数の推移を把握できるグラフを用意しました。こちらも24時間のグラフだと増減がわかりにくかったので3日間のデータを毎日見るようにしています。
# とあるBrowserアプリケーションのグラフをイベントごとに作成
SELECT count(*) FROM AjaxRequest WHERE appName = '<ブラウザアプリ>' TIMESERIES SINCE 3 days ago
SELECT count(*) FROM BrowserInteraction WHERE appName = '<ブラウザアプリ>' TIMESERIES SINCE 3 days ago
SELECT count(*) FROM JavaScriptError WHERE appName = '<ブラウザアプリ>' TIMESERIES SINCE 3 days ago
SELECT count(*) FROM PageView WHERE appName = '<ブラウザアプリ>' TIMESERIES SINCE 3 days ago
SELECT count(*) FROM PageViewTiming WHERE appName = '<ブラウザアプリ>' TIMESERIES SINCE 3 days ago
# とあるMobileアプリケーションのグラフをイベントごとに作成
SELECT count(*) FROM Mobile WHERE appName = '<モバイルアプリ>' TIMESERIES SINCE 3 days ago
SELECT count(*) FROM MobileCrash WHERE appName = '<モバイルアプリ>' TIMESERIES SINCE 3 days ago
SELECT count(*) FROM MobileRequest WHERE appName = '<モバイルアプリ>' TIMESERIES SINCE 3 days ago
SELECT count(*) FROM MobileRequestError WHERE appName = '<モバイルアプリ>' TIMESERIES SINCE 3 days ago
SELECT count(*) FROM MobileSession WHERE appName = '<モバイルアプリ>' TIMESERIES SINCE 3 days ago
SELECT count(*) FROM MobileVideo WHERE appName = '<モバイルアプリ>' TIMESERIES SINCE 3 days ago
SELECT count(*) FROM Span WHERE appName = '<モバイルアプリ>' TIMESERIES
New Relicで取り込みデータ量を削減するには「取り込みデータのサンプリングを実施する」か「Data Drop Ruleを設定してデータの除外設定をする」という2つの方法があります。当時はデータのサンプリングについての検証が行えていなかったため、素直にData Drop Ruleを設定して不要なデータを除外する方向で対応しました。
Data Drop RuleについてはNerdGraphというGraphQLのAPIを利用してデータを除外するためのルールを作成・削除することが可能です。
# drop_dataの例
resource "newrelic_nrql_drop_rule" "foo" {
account_id = 12345
description = "Drops all data for MyCustomEvent that comes from the LoadGeneratingApp in the dev environment, because there is too much and we don’t look at it."
action = "drop_data"
nrql = "SELECT * FROM MyCustomEvent WHERE appName='LoadGeneratingApp' AND environment='development'"
}
# drop_attributeの例
resource "newrelic_nrql_drop_rule" "bar" {
account_id = 12345
description = "Removes the user name and email fields from MyCustomEvent"
action = "drop_attributes"
nrql = "SELECT userEmail, userName FROM MyCustomEvent"
}
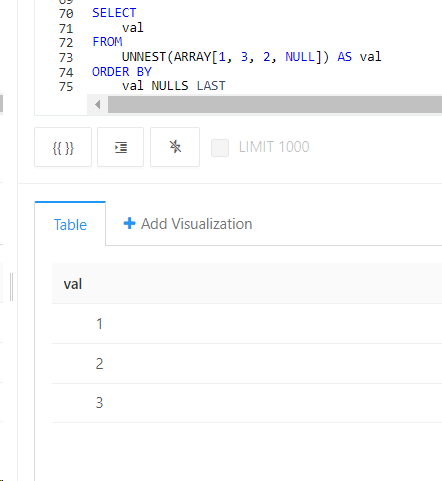
SELECTAVG(val) AS avg_val, --> 3.0MAX(val) AS max_val, --> 4MIN(val) AS min_val, --> 2SUM(val) AS sum_val, --> 6
STRING_AGG(CAST(val AS STRING)) AS str_vals --> "2,4"FROM (
SELECT
val
FROM
UNNEST(ARRAY[2, 4, NULL]) AS val
)
WITH
play_logs AS (
SELECT"xxx"AS user_id,
day,
logs.begin_d ISNOTNULLAS has_played,
FROM
UNNEST(GENERATE_TIMESTAMP_ARRAY(
TIMESTAMP("2023-12-01 00:00:00"),
TIMESTAMP("2023-12-05 00:00:00"),
INTERVAL 1 DAY
)) AS day
LEFTOUTERJOIN (
SELECT
begin_d
FROM
UNNEST(ARRAY[
TIMESTAMP("2023-12-01 00:00:00"),
TIMESTAMP("2023-12-02 00:00:00"),
TIMESTAMP("2023-12-05 00:00:00")
]) AS begin_d
) AS logs
ON
day = logs.begin_d
)
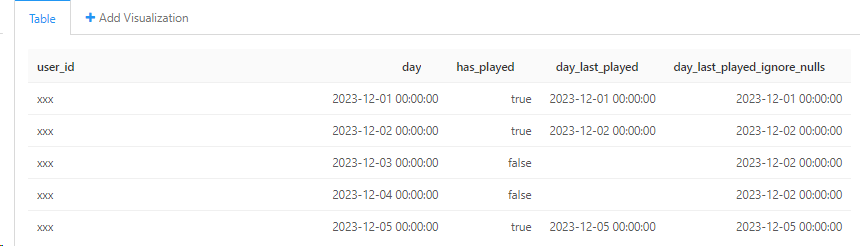
SELECT
*,
LAST_VALUE(IF(has_played, day, NULL)) OVER(PARTITION BY user_id ORDERBY day ASCROWSBETWEEN UNBOUNDED PRECEDING ANDCURRENTROW) AS day_last_played,
LAST_VALUE(IF(has_played, day, NULL) IGNORE NULLS) OVER(PARTITION BY user_id ORDERBY day ASCROWSBETWEEN UNBOUNDED PRECEDING ANDCURRENTROW) AS day_last_played_ignore_nulls
FROM
play_logs