こちらは New Relic Advent Calendar 2022 7日目の記事です。
こんにちは、SREの加我です。
今回はNew Relicのダッシュボードについての設計や工夫について書いていきます。
前置き
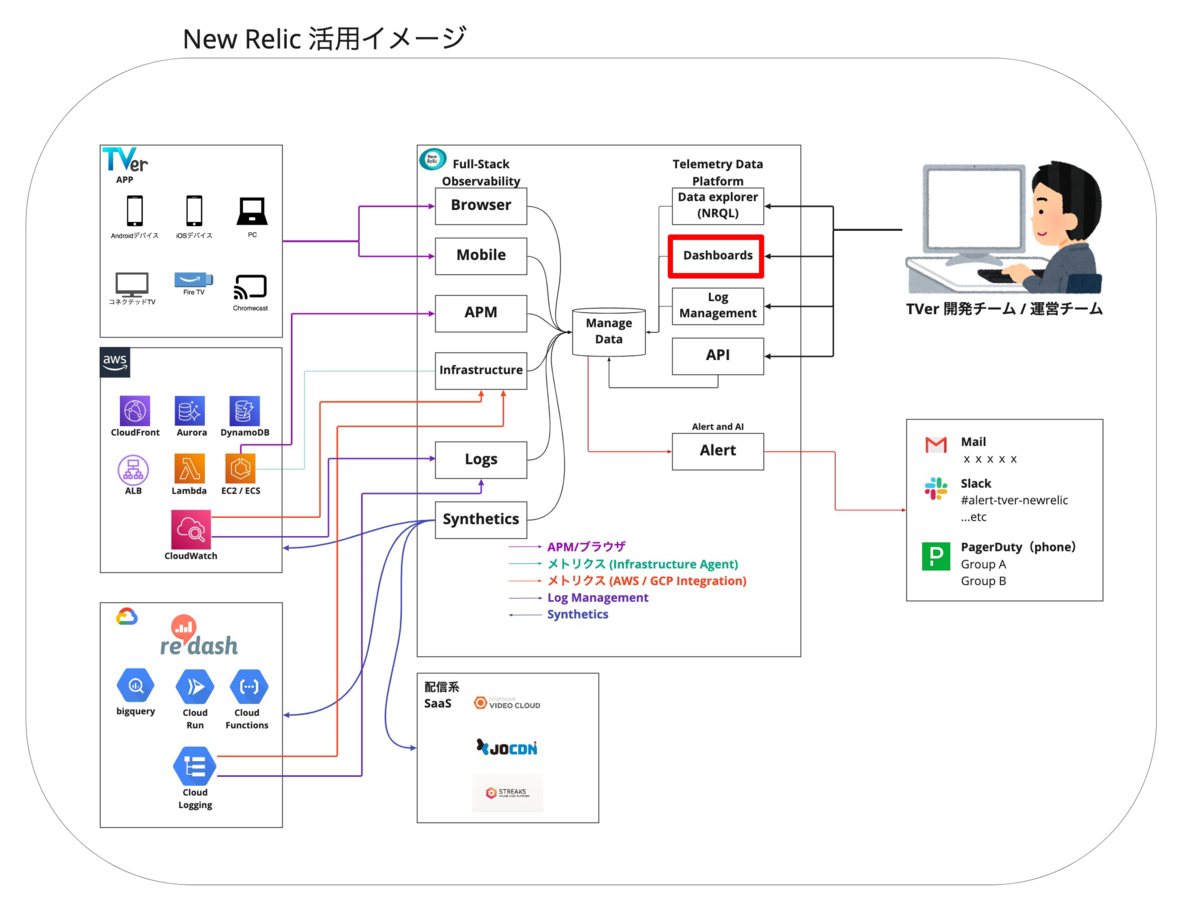
TVerではサービスのモニタリングのためにNew Relicを導入し、日々活用しております。
フロントエンド・バックエンドで発生する様々なテレメトリーデータに対し、New Relicのどの機能を用いてどのように活用していくのかを整理し、概念図にまとめて社内に共有してあります。New Relicは機能が多く新機能の追加ペースも早いため、こういう地味なマッピングが後々活きてくるはずです。
そして今回は図の赤枠にあるDashboards (ダッシュボード) について話していきます。
Developers Summit 2022 Summerなどで触れましたが、TVerには複数のサービスが存在しています。まずはTVerのWebサービス (TVerユーザーの皆様が見ているもの) 、そしてWebサービスと連動するTVer IDの管理サービスを重点的にダッシュボードを整備していきました。

テレメトリーデータとダッシュボード
テレメトリーデータとダッシュボードについて軽く説明を入れておきます。
Google Cloudのサイトではテレメトリーデータについて下記の通り説明されています。
デベロッパー、IT オペレータ、DevOps エンジニア、SRE(サイト信頼性エンジニア)の場合、構築または運用しているアプリのパフォーマンスと健全性に責任があります。アプリケーションが正常であり、パフォーマンスが設計どおりであるかどうかを判断するために使用する情報は、テレメトリー データと呼ばれます。
OpenTelemetry とは | Google Cloud
上記を踏まえて先程のNew Relic 活用イメージを見てみると、サービスを取り巻く様々なテレメトリーデータがNew Relicに集約されていることがわかります。このテレメトリーデータの中から必要なものを整理・ピックアップし、一覧形式で見れるようにするのがNew Relicにおけるダッシュボード機能です。
TVerでのダッシュボード設計
必要なテレメトリーデータの取得ができたので、次はデータを整理するためのダッシュボードを作っていきます。
ダッシュボード自体はUIから数クリックで作れるのですが、如何に使いやすく作り上げることができるのかという点にフォーカスして説明していきます。
うまくいかなかったケース : 詰め込み型
収集したテレメトリーデータを同じ時系列で見て相関や関連を見るというのは重要です。しかし、1つのダッシュボードに全てのデータを詰め込むのはNGです。
見るべきものが散らかってしまったり、すぐ見たいタイミングで必要なデータにたどり着けなかったり、なによりダッシュボードの描画が遅くなってしまうためです。

これを回避するためには必要に応じてレイヤーを分け、見るべきデータを整理していく事が必要です。参考資料の記事内にある「モニタリングをレイヤー分けして可視化する」で詳しく書かれています。
この失敗を踏まえ、次のページ機能について説明していきます。
うまくいったケース : ページ機能の活用
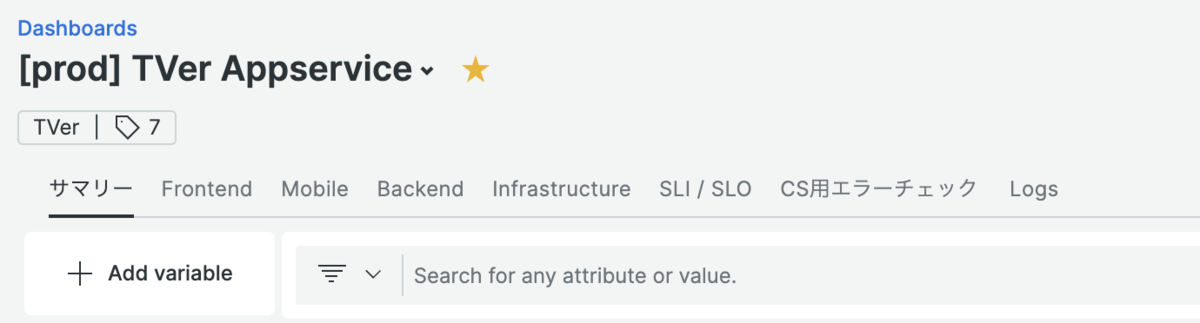
New Relicのダッシュボードにはページ機能があります。
これは1つのダッシュボードの中で複数のダッシュボードを ページ という単位で管理するための機能です。ページはブラウザのタブのように各ダッシュボードを行き来することができます。
ページを活用することでサービスに関わる複数のダッシュボードをグループとして管理することができるため、レイヤーを分けて必要なデータにすぐアクセスすることが可能です。

TVerではフロントエンドからバックエンドまでテレメトリーデータが多岐に渡ります。
そこでページ機能を活用し、下記のようにダッシュボードをグループ化して運用する事にしました。
| ページ名 | 役割 | 主に見る人 |
|---|---|---|
| サマリー | TVerのサービス状況がざっくりわかるメトリクス。 | みんな |
| Frontend | New RelicのBrowserに対応するメトリクス。TVerにおけるWebやSDKなど。 | フロントエンドエンジニア、ディレクター、カスタマーリレーション、SRE |
| Mobile | New RelicのMobileに対応するメトリクス。TVerにおけるiOSアプリやAndroidアプリなど。 | ディレクター、カスタマーリレーション、SRE |
| Backend | New RelicのAPMに対応するメトリクス。Goで動いているTVerのサービスのサーバーサイド。 | バックエンドエンジニア、SRE |
| Infrastructure | AWS関連のメトリクス。 | バックエンドエンジニア、SRE |
| SLI/SLO | TVerのサービスのSLI/SLO。 | ディレクター、SRE |
| CS用エラーチェック | カスタマーサポートにお問い合わせがあった現象の調査用。 | カスタマーリレーション |
| Logs | New Relic Logsに流しているものですぐに調べたいやつ。 | エンジニア全体 |
このうち、サマリー・モバイル・インフラのダッシュボード(ページ)について軽く触れていきます。
サマリー
サマリーに関しては「とりあえずここだけ見て欲しい」という位置づけにしており、フロントエンドとバックエンドのテレメトリーデータから必要なものをピックアップし、デイリーおよび逐次でチェックするために使用しています。
NRQLの COMPARE WITH 1 week ago を使用することで前週比のデータを表示することができるため、例えば「今週の番組は先週と比べてリクエスト数に変化があるか」「今回の特番はそれが行われなかった前週と比べてリクエスト数に変化があるか」という疑問に応えられるものとなっております。


現時点ではSLI/SLOを別のページに分けているのですが、本来であればここにあるのが自然だと考えます。なので将来的にはこのページに加わることでしょう。来年の私の頑張りに期待です。
モバイル
モバイルに関しては上記の通りNew RelicのMobileに対応するもので、アプリケーションのクラッシュやネットワークエラーを確認できるようにしています。
Mobileについてはアプリケーションのバージョンという要素が関わってくるため、最新のリリースと全てのリリースとでグラフを出し分けています。最新のバージョンで改善されているものもあれば、改修により新たな問題が発生してるケースもあります。それをしっかり捉えられるようにしてあります。

インフラ
インフラに関してはNew Relic ⇔ AWSでIntegrationしたメトリクスを確認できるようにしています。CloudWatch LogsからNew Relicに飛ばしてあるものに関してはここのページではなくLogsのページで確認できるようにしてあります。
個人的なこだわりとして、メトリクスは画面上部から ユーザーに近い順 で並べられるように意識しています。ダッシュボードを開いて上から順にメトリクスを見ていけばトラブルの切り分けができるであろうという理由からです。 なので、Synthetics → CDN → LB → Compute → DataStore → Application Integration (SQS・SNS) みたいな感じで並べてあります。


まとめ
TVerにおけるNew Relicのダッシュボード設計・運用について書いてみました。
入門監視 という書籍に書いてあるフレーズですが、監視は育てるものです。ダッシュボードも作って終わりではなく、改善を繰り返しながら育てていく必要があります。
今あるダッシュボードがベストとは思っていませんが、少なくとも実際に運用してみて組織とプロダクトにフィットしているというのも事実です。
今後も継続的にダッシュボードの改善を行いつつ、他のマイクロサービスのモニタリングも同じ粒度でやっていく所存です。
ところで、ダッシュボードの設計・運用についてぜひ各社SREのみなさんとお話してみたく、ダッシュボード意見交換会みたいなのをやってみたいなーと思っております。
New Relic様、NRUGの皆様、イベントの開催についていかがでしょうか?
ダッシュボードの参考資料のご紹介
最後に1つ、私が個人的にとてもお世話になっているブログの記事を紹介したいと思います。
株式会社グラニ様のモニタリングに関するブログ記事です。私がダッシュボード作りで悩んでいた時にこの記事を読み、以降全てのダッシュボードの参考にさせて頂いています。
2017年の記事でDatadogの活用に関するものではありますが、使用しているモニタリングのSaaSに関係なく今でも活用できるアイディアに溢れています。
もし読んだことが無いよという方がいましたら、これを機にぜひ。
engineering.grani.jp