はじめまして。山根と申します。データ基盤の運用保守をしています。
今回は TVerメンバーによるアドベントカレンダーの8日目の記事になります。
タイトル通り、Amazon Aurora MySQLのデータを BigQueryに転送している話を紹介したいと思います。
背景
弊社では、TVerで公開するコンテンツをAurora MySQL(AWS)上で管理しています。
一方で、視聴データなどのデータ分析基盤は BigQuery(GCP)上に構築されており、
コンテンツのメタデータを利用するためにはMySQLのデータをBigQueryに取り込む必要があります。
今回は分析用途のため、1日に数回MySQL snapshotをとり、BigQueryに転送するシステムを構築しています。
考慮事項
考慮事項は以下の通りです。
運用コストを低くかつ不要な情報は取り込まないことを意識しました。
できるだけ分析時のコストを減らす
- Hive Partitioninigを活用してGCSの必要なファイルのみ直接クエリ*1することで、スキャン費用を減らす
機密情報 (コンテンツ運用者のメールアドレス等) は一切GCP側に入れない
アーキテクチャ
システム構成です。
AWSのsnapshotをparquetとして出力するサービスと、BigQueryのparquetを外部テーブルとして直接読み込む機能の相性がよく、
ほぼファイルを置くだけで完結しています。
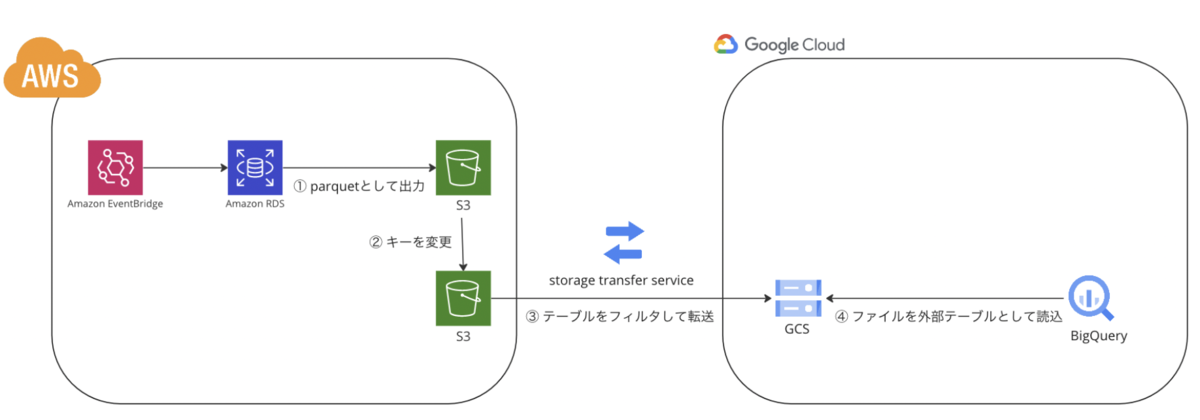
以下、各サービスについて補足します。
① parquetとして出力
- RDSのsnapshotをS3に出力する機能*3をLambdaから呼び出して、S3にmysqldumpを出力しています。
② キーを変更
- BigQueryから読み込めるように、あらかじめバッチ実行日時でHivePartitioningさせたキーにしておきます。以下のようなキー名としています。
s3://${BUCKET}/gcp_export/${TABLE}/year=${yyyy}/month=${yyyymm}/day=${yyyymmdd}/hour=${yyyymmddhh}/${FILENAME}.parquet
③ テーブルをフィルタして転送
- 運用者や、明らかにデータ活用に必要でない情報が入っているテーブルを設定で転送から除外します。
Storage transfer serviceの設定から、gcp_export/${TABLE}から始まるプレフィックスで転送のフィルタを設定することができます。
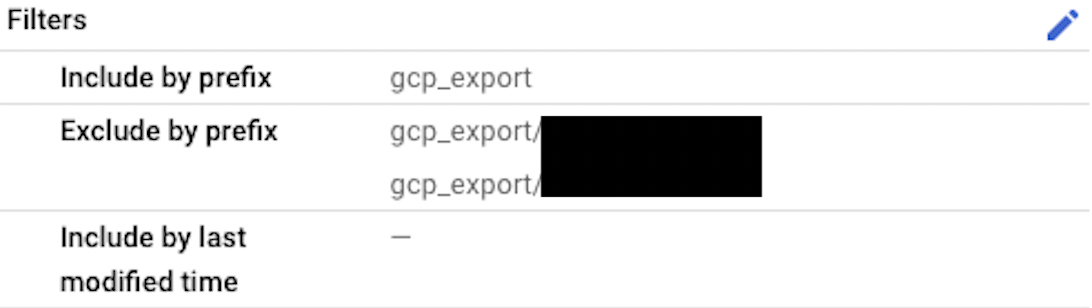
同じように、Advanced transfer optionsの、When to overwrite で、If differentを設定することで、同じファイルの転送をスキップすることができます。

これを用いて、転送間隔を短めにすることで、自動リトライのようなことができます。

④ ファイルを外部テーブルとして読込
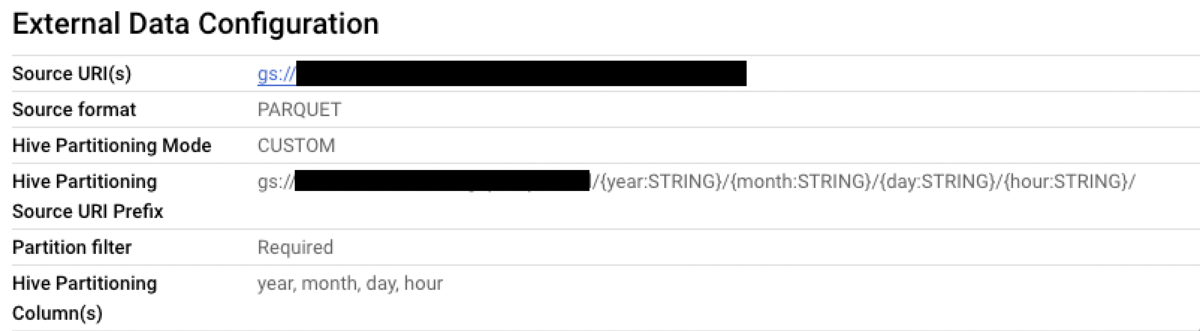
- BigQueryのテーブルごとに以下のようなファイルを読み込む外部テーブルを作成しています。
ファイル名
gs://${BUCKET}/gcp_export/${TABLE}/*.parquetHive Partitioning Source URI Prefix
gs://${BUCKET}/gcp_export/${TABLE}/{year:STRING}/{month:STRING}/{day:STRING}/{hour:STRING}/
year, month, day, hour単位でファイルを読み込めることができるようになりました。
よかった点
GCPのStorage Transfer Serviceが高機能で、同じファイルは自動的に転送をスキップしてくれるので、
単に細かい粒度で転送の設定をしておくだけでリトライができるのが便利でした。
また、AWSのroleでStorage Transfer Serviceのサービスアカウントを信頼するように設定しておく*4ことで、アクセスキー IDとシークレットアクセスキーの管理が不要だったのも便利でした。
データ分析をする際にも
日付でHive Partitionキーを設定したparquetファイルを配置することで、日付と列指定でうまくスキャン量を減らせているのかなと思います。
下記は1日以内の最新のepisodeテーブルを読んでいる例です。このようにdayで参照するGCSのパスを絞ることでスキャン量を減らすことができます。
社内ではこれをCTEにしたものをRedashのQuery Snippetに登録しています。
SELECT * FROM `${DATASET}.episode` WHERE day BETWEEN FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)) AND FORMAT_TIMESTAMP("%Y%m%d", CURRENT_TIMESTAMP()) QUALIFY ROW_NUMBER() OVER(PARTITION BY id ORDER BY hour DESC) = 1
改善点
MySQLのカラムの変更に自動追従できない点です。
BigQueryのGCSへの外部テーブルを定義した時点で、スキーマが決定されてしまうため、
その後MySQL側のカラムが増えても、BigQueryでそのカラムをクエリすることはできません。
こちらは、GCP Batchで定期的に外部テーブルを作成し直すことで対応しようと考えています。
まとめ
AWS RDSのsnapshotをS3に保存し、GCPに転送・BigQueryの外部テーブルとして読み込むことで、
MySQLのテーブルをBigQueryのテーブルとして読み込むことができました。
AWSとBigQueryとの連携については、BigQuery DataStream や BigQuery Omniなど、
新しいサービスが増えてきています。
自分もキャッチアップして、TVerサービスに活かしていければと思っています!
*1:https://cloud.google.com/bigquery/docs/hive-partitioned-queries-gcs
*2:https://cloud.google.com/storage-transfer/docs/filtering-objects-from-transfers?hl=ja
*3:https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_ExportSnapshot.html
*4:https://cloud.google.com/storage-transfer/docs/source-amazon-s3?hl=ja#federated_identity