ログを見ているだけで一日が終わることがありますし、なんなら休みの日もログを見ていたい森藤です。
これは TVer AdventCalendar 2022の5日目の記事になります。 続きはこちらです
TVer ではログを自社基盤で収集していますが、基盤のアーキテクチャなどは多分誰かがどこかで書くとして、私は「クライアントがログを送るときにどういう事を考えて設計していたか」を本記事で紹介します。
本記事では「ユーザ行動の分析を行いアプリケーションを改善する」「ユーザの振る舞いを知ることで施策につなげる」を目的としたポリシーの紹介であり、「システムのログレベルの設計」「LTSV や nginx / apatch 等のフォーマット」「セキュリティ監査」がスコープではないことをご承知おきください。
また、本記事は書き出したら思いの外、長くなったので2部作として分割しますので、ご興味あれば後半も読んでいただければありがたく思います。
TL;DR
- ユーザ理解・施策遂行に必要な行動ログを取得するときの設計ポリシー・考え方について <= 今回はここ
- ログとして記録する情報の整理 <= 今回はここの前半
- 「ユーザの状況・思い・リテラシなど」を再現する逆変換関数を求めることで改善をやっていき!
背景・本記事のスコープ
アプリやウェブサービスの UI 改善やユーザ行動を元にしたロイヤリティでのセグメントを行いたいと思ったとき (例えば GA などの導入) に「ログ 設計 ポリシー」で検索された方はあるあるだと思いますが、この検索クエリではなかなか「ユーザのどういう行動をどういう設計で取得すればいいのか」という問いに回答できる検索結果は得られません
とはいえ、分析を行うために、何らかの指針が欲しい、と迷ったときに検討する材料になればと思い、銀の弾丸ではありませんが TVer での例を紹介します。
その前に
2022年4月のリニューアルの際に、 TVer ではユーザの行動ログを収集する基盤を並行運用は残るものの原則独自実装のものに切り替えました。 それまでは GA を始めとして複数のログベンダおよび Web サーバや API サーバのログを収集し、これらを Google BigQuery に蓄積していました。 ただ、この状況での課題として下記のものがありました
- ログにおけるユーザ/端末の定義が異なる。そもそも 3rd party ・ Apple ATT によるベンダをまたいだ Cookie / IDFA の突合率の低下
- 複数の SaaS におけるログフォーマットにおける知識を持たなければ分析自体スタートが難しい
- アプリの場合は曖昧ではありますが、セッションの定義が一貫していない
全部致命的に辛いのは辛いのですが、事業を考えると特に1が、分析担当のスケールを考えると2が、そして結局の所3番めの他社ログベンダを利用しているがゆえ、中身がブラックボックスであることにリスクを感じていました。
もちろん、1つ1つはエンジニアリソースなどを考えるととても良いとは思うのですが、例えば広告効果のために Adjust を、行動ログに GA を、 TVer 自体の機能系のログは自社を、とするとこれを分析することは伝統芸能の組木細工のような練度がもとめられる代物でした。

上記課題解決のために自社ログシステムに切り替えるに至りました。
このときに、「では、どのようなフォーマットでログを収集するか」「どのようなことを考えてログを収集するか」などを改めて再定義することにしました。 この作業はエンジニアだけでも不完全になりますし、分析担当だけでも不完全になります。双方で議論をするか、両方の経験がある人間が設計に加わることが必要だと思います。
改めて大目的
この設計において、私が目的としたのは「ログを通して、ユーザの行動はもちろん、ユーザがどういう思い(ないしは無意識)で、どういう状況にあったのかを再現できるようにログを収集する」としました。 これは、ある種の生物における認知器官をイメージのアナロジーでした。 人間は目・網膜などの感覚器を通し外的な刺激を得ています。しかしながら網膜は2次元であるため3次元である世界を再現するための情報は不完全であるため、我々は脳内で「刺激から世界」を再現する不良設定問題を解く(デコードする)必要があります。 世界→刺激という順方向での関数(エンコード)に対して、脳内における刺激→世界は逆方向の関数(デコード)になっています。 私達は、得られる刺激から世界を再現・推定し、それに対して働きかけることで世界に対して干渉し、目的を達成していると言えます。
これと同じように私達は TVer を使っているユーザが、どのような状況(電車内?ベッド?食事中?)でどのような思い(毎回見ているドラマを見るぞ!ちょっと暇だから面白いコンテンツはないかな?)で、どのようなリテラシなのかといった世界を直接知ることはできません。 状況・思い・リテラシなどユーザを世界とするならば、それが順変換として行動の一挙手一投足のログに現れ、私達はこの一挙手一投足をできる限り多く収集することでログから世界であるユーザを推定・再現することでユーザに対して適切な情報や UI を提供できるのではないかと考えています。
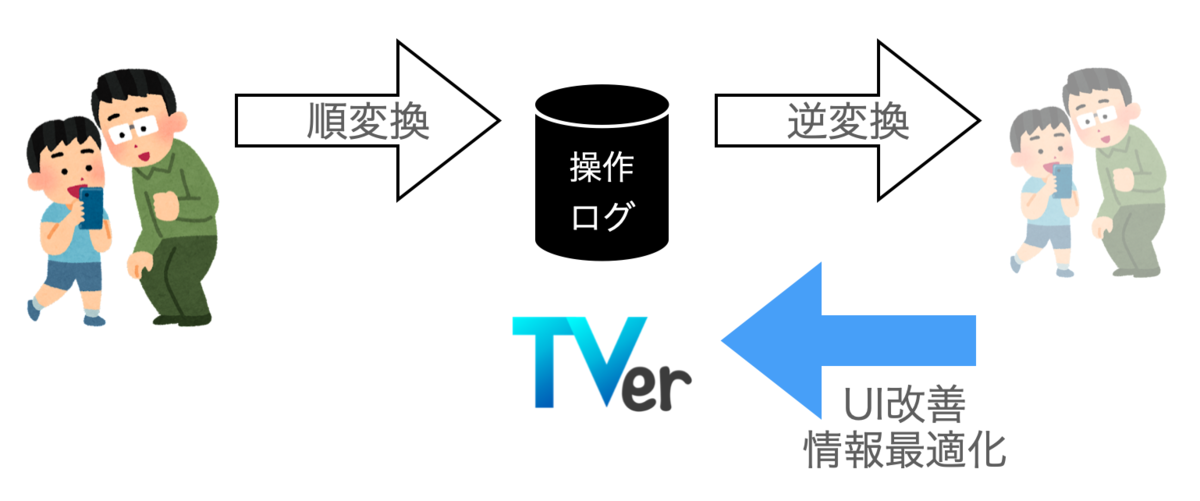
この考え方から、 TVer のログは「きめ細やかなユーザのリテラシ・思い・状況まで想像できるデータを取得する」を大方針とすることにしました。 (弊社、社員数の割には、個人情報保護士が4名もおり、また、個人情報保護法に強い弁護士先生も後ろにいてくださっており全力で個人情報保護法/ユーザのプライバシー保護に寄り添っています!)
ただ、もちろん、ログは取れば取るだけコストになって来ますので、事業とバランスを取って粒度を決めていくことが必要であることは言うまでもありません。
私がこの観点で非常に好きな資料が DeNA での「ゲームの楽しさを定量的に表現」の発表です。
まさにこの図で書かれているものはデータからユーザの思い「楽しさ」を順逆変換モデルにより推定し、それを元にしたビジネスやユーザ体験の改善を行っていることにほかなりません。

採取フォーマット
では「きめ細やかなユーザのリテラシ・思い・状況まで想像できるデータ」とはどのようなものか、また、 GCP BigQuery に格納する際に適切な格納を考えた方法はどのようなものかを同時にクリアする必要があります。
- 情報量
- できる限りリアルタイム (インターネッツが光の速度になっても、光が速度を持つ以上真なるリアルタイムはない)
- 「よくある分析」に基づいた、 dataset / table (wildcard table 含む) / partitioning key / cluster fields の設計
情報量設計
きめ細やかなユーザのリテラシ・思い・状況を知るために TVer では採取する情報の区分として下記のように整理しました。 フィールドはあくまで例で、取得しているものもあればそうでないものありますし、備考に記載してる例なども実際のものとは異なります。
| 区分 | フィールド例 | 備考 |
|---|---|---|
| Who | ユーザ識別子 | 1st party 自社識別子 |
| Who | デバイス種別 | SDApp/TVApp/WebAppなど |
| Who | OS種別 | ios/androidなど |
| Who | 広告識別子 | ADID/IDFA |
| Who | UA | ユーザエージェント |
| When | 送出時刻 | |
| When | 受領時刻 | |
| When | 再生開始時刻 | |
| Where | URI (Web の URL および App の deeplink 相当) | |
| Where | Referrer | 遷移元 |
| What | 操作内容 | クリック、お気に入りした |
| What | 操作対象 | 要素名 |
| What | 付加情報 |
できる限り汎用性を持たせつつも、どうしても後で付加的な情報を渡したいときは、残念ながら必ず発生します。 そのために、ある程度の柔軟性を持たせ一部自由記述ができるフィールドとして付加情報も用意してあります。
これを一貫することで、どのようなユーザが、どこの画面を見ているときに、どのような要素をどのタイミングでクリックしたかを漏らさず記述することができます。
What 記載内容
操作内容および操作対象の記述方法として URI と同様の記法を適用してあります。
操作における click や view はシンプルですが、他方、お気に入りの追加・削除という操作は fav/add 、 fav/remove とするなどある程度の操作内容を先頭マッチで区別できるようにしてあります。
これは後編で紹介する BigQuery で格納するときに有効に効いてきます。
また操作対象は XPATH *1 に近い設計としています。 TVer では「ランキング」や「まもなく配信終了」など、多くのリスト表現が用いられています。 このときに同じエピソードであっても時と場合で順番が入れ替わります。 そうなったときにあるコンポーネントの中の何番目の要素をクリックしたかをログから知ることができるようにするためです。
記述例として下記のようにしてあります。
/${縦方向順序}/${コンポーネント種別}/${横方向順序}/${コンテンツ種別}/${コンテンツID}
コンポーネントは TVer では完全ではないまでも Atomic デザイン*2をいくばくか取り入れて実装し、大枠をコンポーネントと呼んでいます。
- 縦方向順序: ほぼ決め打ちで実装しているものは基本的には 0 が入っていますが、 TVer HOME において「ドラマ新着」「バラエティランキング」「まもなく配信終了」など複数のコンポーネントが縦に並んでいるときに、それらの順序を入れています
- コンポーネント種別: 「ドラマ新着」や「ランキング」「横リスト」「カード型」などの種別が記録されます。これは私の設計漏れでしたが、同一のコンポーネント種別が並んだときに具体的になんなのかがわからないという課題があり現在は次の「横方向順序」との間にコンポーネントIDを埋め込む改善を行おうとしているところです。
- 横方向順序: リスト型を取るコンポーネントである場合に順序が入ります
- コンテンツ種別: タレントだったりエピソードだったり番組シリーズだったり、いろいろなものが入ったときにその種別が入ります
- コンテンツID: それぞれの ID が記録されます
このように設計しておくことで、正規表現で「何が操作されたのか」を簡単にパースできるような設計としています。
デリミタを . (ドット)にしても良かったのですが、コンポーネントやコンテンツ種別などに使いたいシーンがありそうだったのでスラッシュにしています。
また、添字をカッコにしても良かったのですが、ほぼほぼフォーマットが確定しているのでこのようにしました。
よくある課題
- 順序の添字を決めるときは 0 はじまりか、1 はじまりをきちんと宣言しないと後で辛くなります
- フォーマットを変更するときはできる限り同時にやらないと、後で辛くなります
- バッファ領域を設けることはエンジニアリング的に負け感がありますが、つけておかないと後で辛くなります
- どうやって設計してもどこかで泣きます。いい感じのところで諦めて、泣くこと前提で実装しないとどっちみち辛くなります
- どうやっても辛くなります。辛くなる覚悟でやることが心が折れない正攻法です
今回のまとめ
長くなってしまったので今回は前半である
- どのような思想・ポリシーでログを収集しているのか
- 具体的なログに込める情報の整理
をご紹介しました。
次回は続きとして、
- ログをどう整理して GCP BigQuery に格納することでデータシステムとしての保守性を向上させると同時に、クエリ実行時のコスト・速度を改善しているか
- 収集したログから「ユーザの状況・思い・リテラシなど」をどのように再現していくか
をご紹介させていただければと思います。