こんにちは。データ分析だけではなくデータ基盤の設計も考えているのですが、なかなか銀の弾丸は見つかりません。森藤です。
これは TVer AdventCalendar 2022の17日目の記事であり1回目の続編でもあります。
再掲
TVer ではログを自社基盤で収集していますが、基盤のアーキテクチャなどは多分誰かがどこかで書くとして、本記事では「クライアントがログを送るときおよび受け取るときにどういう事を考えて設計していたか」を本記事で紹介します。
本記事では「ユーザ行動の分析を行いアプリケーションを改善する」「ユーザの振る舞いを知ることで施策につなげる」を目的としたポリシーの紹介であり、「システムのログレベルの設計」「LTSV や nginx / apatch 等のフォーマット」「セキュリティ監査」がスコープではないことをご承知おきください。
TL;DR
- ユーザ理解・施策遂行に必要な行動ログを取得するときの設計ポリシー・考え方について <= 前回はこちら
- ログとして記録する情報の整理 <= 今回はここの後半
- 「ユーザの状況・思い・リテラシなど」を再現する逆変換関数を求めることで改善をやっていき! <= 今回はここ
背景・本記事のスコープ
アプリやウェブサービスの UI 改善やユーザ行動を元にしたロイヤリティでのセグメントを行いたいと思ったとき (例えば GA などの導入) に「ログ 設計 ポリシー」で検索された方はあるあるだと思いますが、この検索クエリではなかなか「ユーザのどういう行動をどういう設計で取得すればいいのか」という問いに回答できる検索結果は得られません
とはいえ、分析を行うために、何らかの指針が欲しい、と迷ったときに検討する材料になればと思い、銀の弾丸ではありませんが TVer での例を紹介します。
ログとして記録する情報の整理・システム
リアルタイム設計
「可能であればクライアントでログがうまれた直後、なんならユーザが触っているのをなんとかリアリティで体感したい」という希望はデータを見ている人なら理解してもらえると思います。 「思い・感情」は情報からはわからないけれど操作画面の視覚情報、スマホを握る握力、画面をタッチしているときの指の圧力まで感じて、そこから逆変換によって感情を推定したい、という思いがあります。
とはいえ、それはまだ現実的ではないので、TVer ではログをできるだけきめ細やかに回収しているのですが、同時にも知りたいのです。
クライアントがログを送出した時刻()、サーバが受信する時刻(
)、DataLake まで到達する時刻(
)、DataWarehouse まで到達し実際にクエリとして記述ができる時刻(
)にはどうしてもラグが生じますし、コストを考えるとより一層
の時間間隔は、どうしたって広がってしまいます。
実際にクエリをかけたり分析を行うことが可能になるまでの時間差とそれを実現するシステムコストの間でせめぎあいつつ折衷案を出していくことがデータエンジニアの腕の見せ所でもあり、データ分析担当者のシステムへの理解とサービサー側との折衝能力といっても過言ではありません。
例えば、リアルタイムでのトリガー、例えば「初回お気に入り登録したときにユーザにその利便性をアプリ内メッセージでお伝えしたい」というサービサー側との希望を満たしつつ、コスト安く翌日以降にデータを分析することを両立する設計はなかなか難しいものになります。 (これについては別エントリで書くようにしますが、 TVer ではこのような用途にもある程度耐えうるように設計しています。)
BigQuery では Streaming Insert という機能があり、1ログをそのまま Stream で投入し、即分析可能にするというものがあります。 現実的にネットワークの限界をリアルタイムと呼ぶのであればこの方法が一番良いのですが、 Streaming Insert は高いのです。 $0.012 per 200 MB の金額になります。 単純に 100GB 保存すると 840円がかかります (円安ぅぅぅぅ)。仮にこれが1日分だとすると、一年で30万円、1TBなら3000万円なので無視できない金額になります。
これに対してファイルアップロードは現在無料です。 そこで TVer では1リクエストをそのまま入れるのではなくクライアントから受けたログを一度ファイルに記録し、一定間隔で GCS に書き出し、これを読み取れるようにしています。 この方法では場合によってはログが重複して投入される可能性もあるのですが、ログの重複は対応可能でも、欠損はどうにもならない、ということを考え「more than one」のポリシーで、 BigQuery Streaming Insert をできる限り使わずコストを下げるようにしています。
このあたりも「ログのリアルタイム処理」と「ログによる事業コミット」のバランスを取る必要があるところです。
データ保持設計
ここから少し、ログそのものの話ではなく、 GCP BigQuery の話になりますが、お付き合いください。
外部テーブル
先程 GCS に書き出して、読み取れるようにしている、と書きましたが、実は、ここで file upload はしていません。
BigQuery では外部テーブルというものを作成することができます。これは GCS を直接参照しクエリをかけることができる機能で、 AWS S3 を直接参照する AWS Redshift に相当する機能です。 TVer では前述の通りログを Streaming Insert によるリアルタイム処理はコストの問題から諦め、 GCS に吐き出し、これを外部テーブルによって参照しています。
このように GCS を直接閲覧することで比較的ログ到達時間にリアルタイムに近い間隔でクエリを書けることができます。 しかしながら外部テーブルはどうしてもクラウドストレージから読み込むまでのオフセット時間がかかります。 ですので直近の僅かなデータであれば直接外部テーブルを参照することでもいいのですが大量のデータを分析する場合には分析担当としてはストレスになります。
これに対応するために、一定間隔のバッチ処理で外部テーブルから Native Table として書き出しています。 両者をマージした view を用意することでラムダアーキテクチャに近い処理を隠蔽して、分析担当にとってはリアルタイムでログを処理できるようにしています。
雰囲気としてはこのようなクエリでの view になります。
WITH realtime_logs AS ( -- 直近のログ (_TABLE_SUFFIX で実行時刻に近い最新のものはこちらを参照する) SELECT * FROM `myproject.mydataset.external_table_logs*` WHERE _TABLE_SUFFIX BETWEEN FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR)) AND FORMAT_TIMESTAMP("%Y%m%d", CURRENT_TIMESTAMP()) UNION ALL -- 処理済みのログ (_TABLE_SUFFIX で集約化された古いデータ) SELECT * FROM `myproject.mydataset.native_table_logs*` WHERE _TABLE_SUFFIX < FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR)) )
外部テーブルを利用するときに注意点としては下記になります。
- BigQuery をかけるユーザ/ServiceAccount に対する GCS 読み込み権限(Legacy Bucket Reader / Legacy Object Reader)が必要
- どうも Connector によりうまいこと解消ができそう (取組中)
- Hive Partitioning のキー戦略が非常に重要
分割戦略
BigQuery におけるデータテーブルの分割方法にはいくつかの方法があります
- ワイルドカードテーブル: サフィックス (数字とすら限っていない)を変えた個別のテーブルを作成する方法。 Query 実行時の TABLE 指定でサフィックスを
*とすることで_TABLE_SUFFIXに任意の制限をかけ、あたかも1つのテーブルのようにクエリをかけることができます。特にサフィックスを数字8文字 (YYYYmmdd) としておくと BigQuery 側でいい感じにまとめた表現にしてくれます。 - Partitioning Key: テーブルのフィールド1つを(ファイル分散の)分割キーとして指定することで、走査範囲を制限し、コストを安く、時間を短くすることができます
- Clustering Table: クラスタリングフィールドを指定することで (2022/12時点では最大4つ) 、ストレージブロックを分割して保存することができます。これによりクエリ実行時に走査範囲を制限し、コストを安く・速度を早くすることができます。クラスタリングについては Introduction to clustered tables | BigQuery | Google Cloud を参照してください。
弊社ではこれらを組み合わせてログを適切に分割しクエリ実行時のコスト・速度の最適化を行っています。
- 用途に応じてテーブルを分割
- 閲覧ログ (view ログ): 各種アプリの閲覧した記録を保持します。各画面の訪問回数だけを分析することは多くあるために個別のテーブルとしてデータを保存しています
- 視聴ログ (audience ログ): 動画の視聴データを記録しています。再生、停止、完了、早送り/戻し/シークバー操作、広告入/出、など視聴における細かい操作をすべて記録しています
- イベントログ (event ログ): 同一の遷移先が異なるコンポーネントを経由して移動できる場合、閲覧ログでは取れない要素のクリックや画面遷移を伴わない操作ログを記録しています
- 日付ごとのワイルドカードテーブルとして分割
- 上記ログはすべて日毎に
YYYYmmddというサフィックスをつけて分割して保存しています。これによりシステムのトラブルなど障害時の入れ直しなどを容易にしています - クエリ実行時には捜査範囲を
_TABLE_SUFFIXというサフィックスで制限することで安く・早く実行することができます - それぞれのログに対応する view を貼り、
year = SUBSTR(_TABLE_SUFFIX, 1, 4)、month = SUBSTR(_TABLE_SUFFIX, 1, 6)、day = SUBSTR(_TABLE_SUFFIX, 1, 8)というフィールドを追加することで、あたかも1つのテーブルのようにクエリを書くことができます
- 上記ログはすべて日毎に
- テーブルごとに Partitioning Key によるファイル分割
- 視聴ログ、イベントログに置いては各種 action を設定することで、例えば「再生」という視聴ログだけを取り出すことで再生回数の集計を効率的に分析することが、「お気に入りに追加/削除」というイベントログだけを取り出すことでお気に入りだけを効率的に分析することが可能になります
- Clustering Table によるストレージブロックを分割
保持システムまとめ
このように TVer では
- リアルタイムとコストのせめぎあい
- せめぎあいをリアルタイム等、サービサーに寄せるために実際の格納やクエリ実行時のコスト戦略として各種分割をフル活用している
- 分割しつつも分析者の負担を減じるように view などで工夫している
などを考えてシステムを設計しています。
さらに、先日の黒瀬のエントリ「GCPに構築したシステムを安全に運用するための一時権限付与の仕組みについて」でも書きましたが、個人情報保護法やセキュリティ・不要な権限による事故を意識した権限管理なども含めて検討しています。
状況・思い・リテラシなどユーザの逆変換
先に述べたとおり、私達は直接的に「ユーザの思い・感情・状況」を精緻に描く逆変換関数を手に入れることはできません。 あくまで「ユーザの状況・思い・リテラシから発生する行為の記録」という世界→刺激という順変換された情報を元に、その時その時に最善だと思われる暫定的な逆変換関数を適用することで刺激→世界を推定しています。
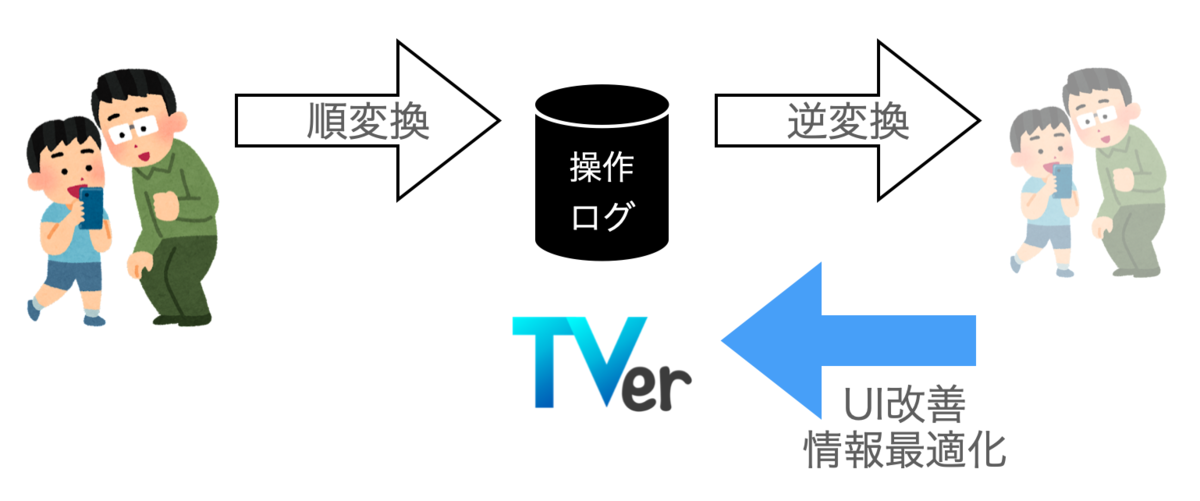
同じように、ログから状況・思い・リテラシなどユーザを推定することで、ユーザの状況・思い・リテラシに寄り添って利便性が高い情報の提供や、適切な画面などユーザ体験の提供さらには不要なもの邪魔なものではなく有用な情報としての広告の最適化までを実現するような施策の計画・実施を効果的に行うことが可能だと考えています。
この逆変換関数をどのように構築するかこそが現在また今後、 TVer が力を入れて取り組もうとしているところです。 これは推定したいユーザの特徴量によって様々なアプローチがあります。 例えば属性などを推定するだけでも、 LightGBM、 xGBoost 等のアプローチや深層学習 、情報量が少なくこれらの適用が難しいユーザに対しては単純なクロス表など効率的・効果的なアプローチを適切に選び実施したり、 IP アドレスの CIDR を利用することで LAN 環境なのかキャリア環境なのかを判断するだけで通信環境にストレスがないネットワークなのかどうか、ギガを節約したいかどうかを元にしてレコメンデーションや動画の解像度を最適化することも可能でしょう。
まだ残る課題は多くありますが、私は TVer 社で、このデータからユーザを想像し、再現する作業を進めていければと思っています。
まとめ
本記事で TVer でのログ収集のポリシーの後段である、データをどう格納することでコスト安く高速に保存するか、そして簡単ではありますしこれからの思いではありますが、それらを利用して逆変換していくかを紹介しました。 このように「ユーザの状況・思い・リテラシを感じることができる」よう精度高く設計したログを収集することで、今後、目的に応じてよりコストパフォーマンスの高い・精度の高い逆変換関数の構築に力を入れて取り組んでいきたいと思っています。
逆変換関数を再現したい!それを使ってユーザ体験の改善や広告事業を成長させたい!というデータアナリスト・データサイエンティストを募集しています。 同時にこれらのログ基盤をより改善するデータエンジニアも募集しています。
ちなみにプレスリリースでも出しましたが、月間で2,300万ユニークブラウザが、月の再生回数が2億5千万回と大量のデータがあります! 超楽しいですよ!
もしご興味があれば一度カジュアルにお話をするところからでもウェルカムです。ぜひご連絡ください、お待ちしております。