はじめに
こちらは TVer Advent Calendar 2025 16日目の記事です。15日目は @ko-ya346 さんの「TVer の分析業務について」でした。
こんにちは、TVer の広告事業領域でデータサイエンティストをしている川井です。普段は TVer 広告の配信システムの開発や、広告効果分析、データ基盤構築などを担当しています。
今回は、TVer 広告のデータサイエンティストが直面する集計業務におけるつらみを解消すべく、dbt Platform を用いてデータ分析基盤を構築している最前線をご紹介します。
広告領域におけるデータ集計依頼
TVer 広告のデータサイエンティストは少数精鋭で日々の業務を遂行しています。分析業務と並行して、営業チームからのデータ集計依頼にも対応しています。例えば以下のような依頼です。
このような多岐にわたる依頼に対して、色々な配信ログを直接参照するような集計 SQL を都度書いて対応していました(現在も一部対応中ですが...)。
サービスのグロースに伴う課題
TVer の広告事業が急成長する中で、以下のような問題が顕在化しました。
依頼の増加と多様化
- キャンペーン数の増加に伴い、配信実績確認の依頼が激増
- 集計粒度の多様化
- 「日次」「週次」といった、様々な時間粒度での集計依頼
- 広告代理店・広告主・キャンペーン・クリエイティブといった、様々な粒度での集計依頼
再現性と効率の問題
- 似たような集計を何度も書き直している
- 人によってデータに対する理解度が異なり、集計作業ですら属人化してしまう
結果として、本来注力すべき分析業務ではなく、集計作業に時間を取られる状況に陥っていました(今も改善中ですが...)。
dbt Platform でデータ分析基盤を整備
このような課題を解決するため、事前に最適な粒度で集計したデータマートを構築し、迅速かつ正確に集計結果を提供する必要があると考えました。 データ分析基盤の構築には dbt Platform を採用し、ベストプラクティスに倣って 3 層構造のデータモデルを構築しています。
- Staging 層
- 生ログからの軽い加工を担当。NULL の COALESCE 処理、エイリアス名の統一など後続処理で扱いやすい形への整形を行う
- Intermediate 層
- ビジネスロジックの適用・結合を担当。ログの突合、種々ロジックなどを実装
- Mart 層
- 分析・可視化用の最終テーブル。営業チームが直接参照するキャンペーン別配信実績サマリや、BI ツール接続用の集計済みテーブルを配置
結果として、136 個の SQL モデルと 57 個の YAML 定義ファイルで構成される基盤が稼働しており、現在も拡張中です。
dbt Platform を選定した理由
スクラップ&ビルドのしやすさ
TVer の広告事業は急成長中のため、レポート要件の追加や集計粒度の多様化、季節性イベントに伴う分析ニーズの変化など、変化が激しい状況です。dbt は SQL ベースでモデルを定義するため、不要になったモデルの削除や新規モデルの追加が容易なことから、このような変化にも柔軟に対応できます。また、YAML でスキーマを定義し、モデル間の依存関係を ref() 関数で明示することで、変更の影響範囲も把握しやすくなっています。
データエンジニアが不在でもメンテナンス可能
専任データエンジニアがいない中で少数のデータサイエンティストが様々な依頼に対応しているため、以下の点でもメリットがあります。
- ワークフローツールの管理運用が不要なため、SQL によるロジック記述に集中できる
- スケジューリングが標準機能として搭載されているため、簡単にジョブ実行頻度を制御できる
- ドキュメントが自動生成されるため、新規にジョインしたメンバーのモデル理解が容易になる
BigQuery との親和性
TVer ではデータ基盤に BigQuery を採用しています。dbt は BigQuery 固有の機能との親和性が高く、日々の運用で恩恵を受けています。
例えば広告配信では、毎日大量のレコードが発生するため、スキャン量の最適化が不可欠です。dbt では SQL モデル内の config() ブロックで partition_by や cluster_by を指定するだけで、パーティションとクラスタリングを適用したテーブルを作成できます。
また、BigQuery 向けのインクリメンタルマテリアライゼーションでは、merge 戦略(MERGE 文による upsert)と insert_overwrite 戦略(パーティション単位の置き換え)を選択できます。配信ログの特性に応じてこれらを使い分けることで、フルスキャンを回避しビルド時間とコストを削減しています。
エコシステムとコミュニティの充実
BigQuery をデータ基盤として採用している以上、Google Cloud ネイティブの Dataform も選択肢でした。しかし dbt はユーザー数が圧倒的に多く、実務での Tips やトラブルシューティング事例が豊富に蓄積されています。少人数チームで運用する我々にとって、「困ったときに検索すれば先人の知見が見つかる」安心感は大きな決め手でした。
また、dbt_utils や elementary といったパッケージのエコシステムが充実しており、汎用的なユーティリティや異常検知の仕組みをすぐに導入できる点も魅力です。
データ品質の担保
dbt の標準テスト機能とカスタムテストを組み合わせ、データ品質を多層的にチェックしています。
標準テストでは not_null、unique、accepted_values、relationships などを活用し、主キーの一意性制約や外部キーの参照整合性、カラム値の妥当性を担保しています。
加えて、データパイプライン固有の問題を検知するためカスタムテストを実装しています。具体的には、直近 N 時間分のレコードが想定どおり存在するかを検証するテストを作成し、上流のデータ取込遅延やジョブ失敗を早期に検知できる仕組みを整えました。
テスト失敗時は Slack 通知が飛ぶようにしており、多方面へ影響が出る前に対処できる体制を構築しています。
現状の運用
現在はチームメンバーが dbt に慣れることを優先し、依頼ベースで必要なデータマートを都度構築しています。「完璧なデータモデルを最初から設計する」のではなく、まずは動くものを作り、運用しながら改善するアプローチを取っています。活用が進み、データモデルが増えてきた現在、次のフェーズとして以下の整備を進めています。
今後の展望
セマンティックレイヤーの活用拡大
dbt Platform の セマンティックレイヤー(Semantic Layer) 機能を導入し、広告ビジネス指標の定義の一元管理を目指しています。一部データモデルでは既にこれを導入しており、Google スプレッドシートの dbt Semantic Layer アドオンを使って、定義されたメトリクスに従った数値をスプレッドシート上で直接取得できるようにしています(下図)。
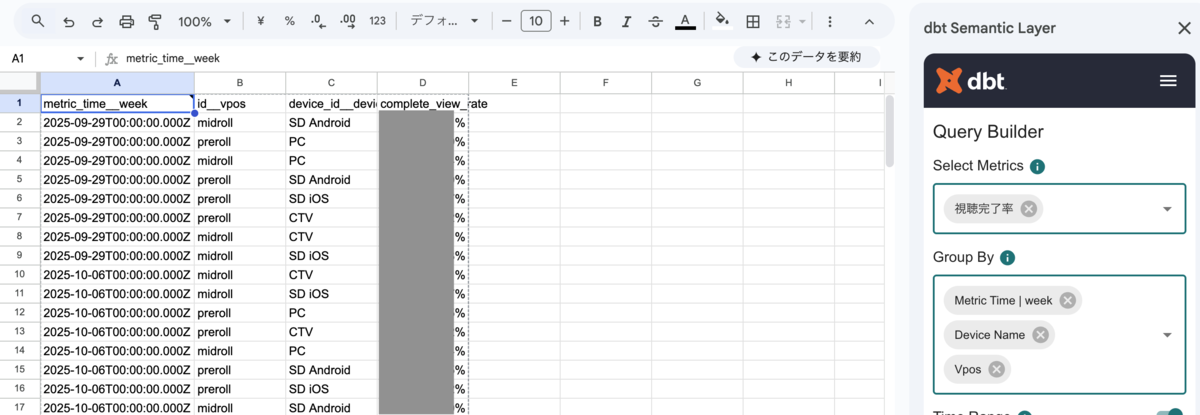
セマンティックレイヤーの導入により、「インプレッション数」や「ユニークユーザー数」といった指標の計算ロジックを YAML で一元定義し、どのツールから参照しても同じ結果が得られる Single Source of Truth が実現可能になります。SQL を書くことなく、デバイス別・日付別など任意のディメンションで指標を参照できるよう整備中です。今後は対象モデルを拡大し、より多くの指標をセルフサービスで取得できる環境を目指していきます。
MCP を活用した自然言語でのデータアクセス
さらなるデータの民主化を目指し、Model Context Protocol(MCP)を活用した自然言語によるデータ分析基盤へのアクセスを検討しています。
dbt Labs が公開している dbt MCP Server を利用することで、LLM がセマンティックレイヤーで定義されたメトリクスやディメンションの情報を参照し、ユーザーの自然言語による問い合わせを適切な Semantic Layer API 呼び出しに変換できます。現在 PoC を進めており、「先週のデバイス別視聴完了率を教えて」といった問い合わせに対して正しい結果を返せることを確認しています。
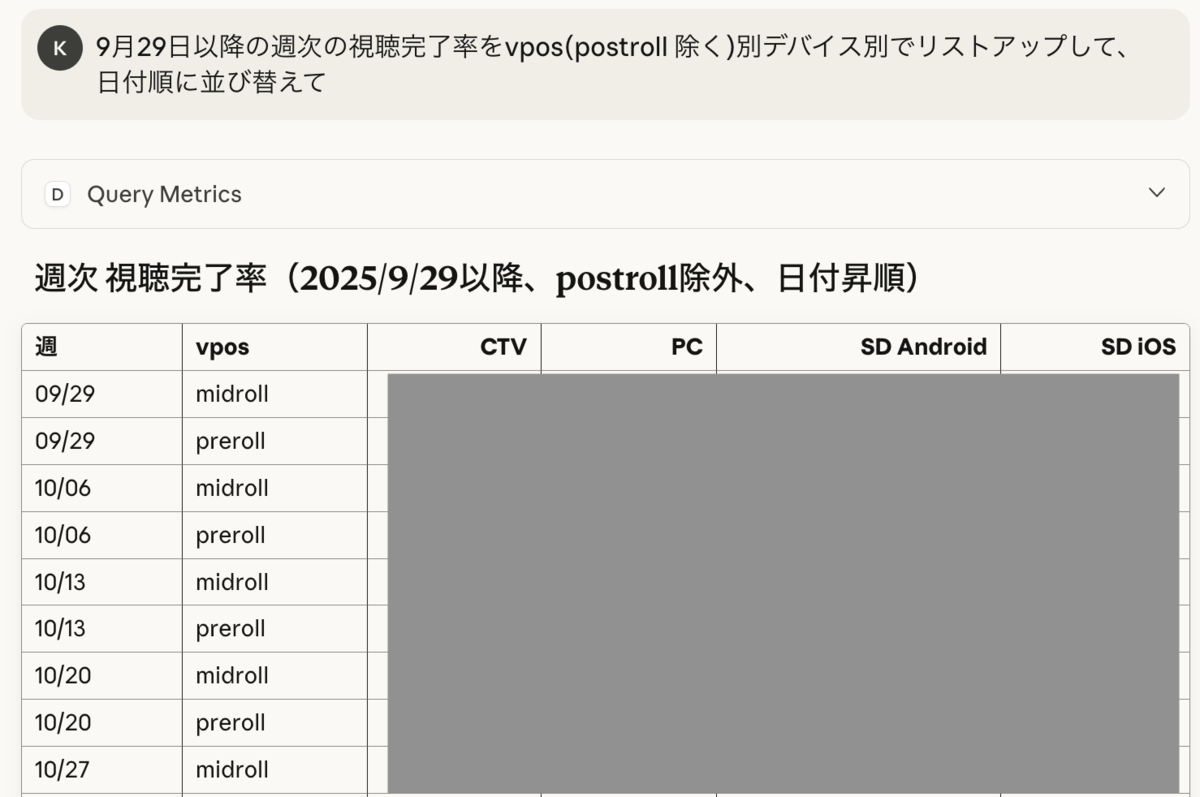
今まで我々のチームに依頼していた内容をそのまま自然言語で問い合わせられる環境を整備し、データリテラシーに依存しない情報アクセスを実現したいと考えています。
終わりに
TVer では、広告事業の成長を支えるデータ基盤の構築・運用に一緒に取り組んでくれる仲間を募集しています。
- ビジネス価値を引き出すデータモデリングに興味がある方
- dbt や BigQuery を使ったモダンなデータ基盤に挑戦したい方
- 「分析のための分析」ではなく、事業成長に直結するデータ活用を実現したい方
ご興味のある方は、ぜひカジュアル面談からお話しましょう!
https://herp.careers/v1/tver/ARm9gwwiv3zS
明日の記事は @NagaiKoki さんの、「Vitestは本当に早いのか? Vitestでテストを高速化するアプローチについて」です。お楽しみに!