
こんにちは。データエンジニア 遠藤(TVerにJOINしてまだ3ヶ月)とアドテクエンジニア 鶴貝です。
2023年8月29日~31日にGoogle Cloudの技術カンファレンスGoogle Cloud Next '23がサンフランシスコで開催されました。(4年ぶりのオフライン開催)
弊社では、民放公式テレビ配信サービスTVer・TVer広告のデータ分析で用いるビッグデータ基盤にGCPを採用しています。そこで、先述したエンジニア2名がGoogle Cloud Next '23に現地参加させて頂きました。
Next '23ではGCPの新機能リリースや世界中での活用事例が多く紹介されました。本記事では、Next '23で発表された話題のうち、BigQuery data clean roomsを重点的に報告します。
さらに、サンフランシスコまではるばる出向きましたので、撮って出し写真と共にGoogle Cloud Next '23の様子をレポートします!
BigQuery data clean rooms
「What's new with BigQuery」・「Share securely with data clean rooms」の各セッションにおいてBigQuery data clean roomsのPreviewリリースが発表されました。データクリーンルームは他クラウドでは既にリリースされていますが、ついにGCPにも本格的に登場します。
データクリーンルームとは
データクリーンルームとは個人を特定することなくプライバシーを保護しながらデータの分析・利活用ができるクラウド環境のことです。
社外へのデータ共有は、集計結果のメール送付や共有サーバへのアップロード・社内ネットワークへのアクセス権限を関係者に付与…といった方法が一般的でした。しかし、従来の共有方法では運用を一歩間違えれば意図しない第三者へのデータ漏洩・不正アクセスの発生といったリスクがあります。
さらに近年では、法規制・ベンダーのトラッキング規制に伴うデータ利用の厳格化、個人情報取扱いに違反すると社会問題にまで発展…といった新たな問題も勃発しています。
そのため、リスクを最小限に抑えた効率的なデータ共有の必要性がますます叫ばれています。そこで、データの提供側と利用側それぞれの不利な点を解消しながらデータ共有する技術がデータクリーンルームです。
Ads Data Hub・Analytics Hubを経てのリリース
BigQueryは、IAMユーザに適切な権限を付与すれば、BigQueryデータの他Projectからのアクセスは基本的に可能です。しかし、この運用では以下の問題があります。
- 他Projectにあるテーブル参照はBigQuery WebUI的に不便(例:アクセスできる他ProjectのテーブルはBigQuery WebUIのサイドバー「エクスプローラ」には載らない)
- 組織外に公開したBigQueryテーブルに対する組織外アカウントの使用状況がテーブルを所有するProjectから把握できない
- 他組織に対してデータ取得に関する細かな制御条件が設定できない
一方、GoogleではAds Data HubとAnalytics Hubという機能が既に提供されています。
Ads Data Hubは、Googleの広告プロダクトのデータとクライアントが保有するデータを突合する機能です。
また、Ads Data Hubは以下の特徴があり、プライバシーを考慮したユーザレベルでの広告分析を可能にしています。
- ユーザIDのような個人レベルの情報は一切出力されない
- 集計結果が一定の閾値未満の場合は集計結果の数値自体出力されない
- Google Ads・Display & Video 360のデータと広告主データ間の共有のみに限られる(=用途がGoogle広告の分析のみに限定される)
昨年BigQuery上でGenerally Available(GA)になったAnalytics Hubは、BigQueryオブジェクト(テーブル、ビュー、MLモデル)を組織間で共有できる機能です。
共有する側(プロバイダ)が公開したいDatasetをExchange/Listingとして登録してShared Datasetに追加します。一方、共有される側(コンシューマ)はListing検索して、プロバイダのShared DatasetをLinked Datasetとして自分のProjectに登録します。これにより、Project間のDataset共有が容易に実現できます。
つまり、Ads Data Hubのプライバシー保護に特化した特徴をAnalytics Hubに適用した機能がBigQuery data clean roomsです。(そのためBigQuery data clean roomsはAnalytics Hub上の機能としてリリースされます)
BigQuery data clean roomsを実際に使ってみる
BigQuery data clean roomsでは以下の手順でデータクリーンルームを作成・運用します。
- BigQueryでデータクリーンルームを使用できる状態にする
- プロバイダ側でデータクリーンルームを新規作成
- コンシューマ側でデータクリーンルーム参照を設定
- コンシューマ側がデータクリーンルームからデータを抽出する
1. BigQueryでデータクリーンルームを使用できる状態にする
まず、BigQueryでデータクリーンルーム機能を使用するには、プロバイダ・コンシューマの各Projectで以下の前処理が必要です。
- Analytics Hub APIを有効化
- データクリーンルーム作成・参照設定を行うそれぞれのIAMユーザに対して適切なAnalytics Hubロールを付与
次に、プロバイダProjectにおいてコンシューマへシェアするDatasetとそのDataset上に存在するViewをあらかじめ新規に作成します。なぜなら、データクリーンルームは、Analytics HubのExchangeとは違い、Viewのみ共有されるからです。(テーブルは共有されません)
そのため、データクリーンルームでは以下のDDL文のような「Privacy Policyを設定した承認付きView」の作成を推奨しています。
CREATE OR REPLACE VIEW `provider_project.cleanroom_share.dcr_provide_data_view`
OPTIONS (
privacy_policy=TO_JSON_STRING(
STRUCT(
STRUCT(
"column_a" AS privacy_unit_columns,
2 AS threshold
) AS aggregation_threshold_policy
)
)
)
AS (
SELECT *
FROM `provider_project.cleanroom_data.dcr_provide_data_table`
)
2. プロバイダ側でデータクリーンルームを新規作成
プロバイダProjectのAnalytics Hub WebUI上で新規にデータクリーンルームを作成します。
2-1. BigQueryメニューから『Analytics Hub』を選択 → 『CREATE CLEAN ROOM』をクリック(下図参照)
2-2. 表示名などの情報を入力してデータクリーンルームを作成
2-3. 2-2.で作成したデータクリーンルームの表示名をクリック → 『データを追加』をクリック

2-4. 共有するDatasetを設定(Datasetを設定すると、共有される予定のDataset内にあるViewがprivacy policy情報とともに確認できます)

3. コンシューマ側でデータクリーンルーム参照を設定
次はコンシューマProjectの設定です。
3-1. BigQueryメニューから『Analytics Hub』を選択 → 『リスティングを検索』をクリック(下図参照)
そうすると、以下の図のように2.で設定されたDatasetがListing検索できる画面が表れます。ここから参照するDatasetを検索します。
3-2. Listing検索からプロバイダ側のDatasetをさがし、選択して、登録
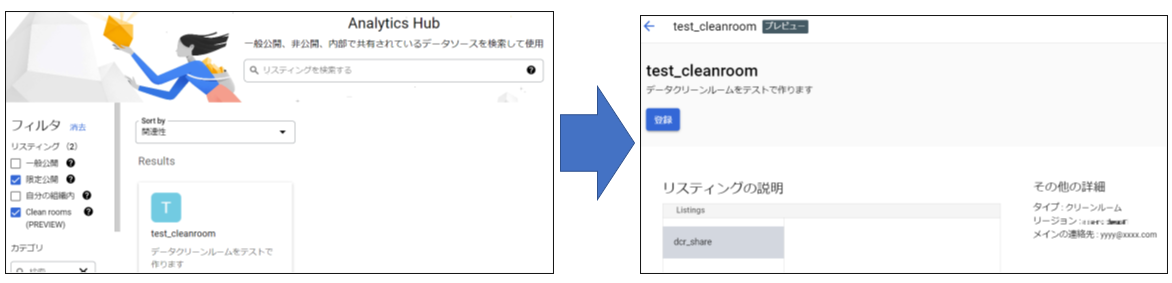
最終的に、コンシューマProjectのBigQuery WebUI中の「エクスプローラ」に表示されるテーブル一覧中に 【Analytics Hub 表示名】_【データ表示名】 という名のDatasetが作成されます。(下図参照)

4. コンシューマ側がデータクリーンルームからデータを抽出する
コンシューマProjectにおいてデータクリーンルーム内のデータを抽出するクエリは以下になります。
SELECT WITH AGGREGATION_THRESHOLD column_b,COUNT(1) FROM `consumer_project.test_cleanroom_dcr_share.dcr_provide_data_view` GROUP BY 1
クエリ内で参照したテーブルのDatasetは3.で参照設定したDatasetであり、まるで自ProjectのDatasetのように扱うことができます。
「SELECT WITH AGGREGATION_THRESHOLD」はPrivacy Policyを設定したViewに対するSELECT句であり、以下の特徴があります。
- 特定の集計関数・GROUP BYをクエリに含めることが最低条件(そのためレコード抽出はできない)
- Privacy Policyのprivacy_unit_columnsで指定したカラムをGROUP BYに含めることはできない(privacy_unit_columnsは個人を特定するカラムを表す)
- Privacy PolicyのTHRESHOLDで設定した数値以上の集計値のレコードのみを集計結果に返す
データ抽出の制約は、現在のPublic Preview時点では『SELECT WITH AGGREGATION_THRESHOLD』句に関連した設定しかできないようですが、Generally Available(GA)時に以下の設定ができるように対応する見込みであると「Share securely with data clean rooms」セッション内で発表されました。(このときにAnalytics HubのExchangeと明確な機能差別化を図ると思われます)
- オーバーラップ分析
- 差分プライバシー
- joinの制限
さらに、データクリーンルームDatasetを参照したクエリをモニタリングする機能が実装されており、プロバイダ側でデータクリーンルームの利用状況の把握が可能です。
おまけ:Google Cloud Next '23 現地参加レポート!
さて、ここからはGoogle Cloud Next '23の模様をレポートします!
サンフランシスコの夏は乾季のため、Next '23期間中はずっと快晴&気温は常に30℃を超えないので、とても過ごしやすい気候でした。
会場は「Moscone Center」というサンフランシスコで有名なコンベンション施設でした。


お昼どきには会場近くの庭でランチが無料で提供されました。(毎日違うメニュー & グルテンフリー・ベジタリアンにも対応していました)


上記の写真は3日目ランチのメニュー表です。
この写真を早朝に撮っていたら準備中の設営スタッフから笑われてしまったので、
「I'm expecting today's lunch time!!」
と伝えました。
スポンサーブースはとにかく規模が大きく、周りがいがありました。

サンフランシスコといえばゴールデンゲートブリッジ。サマータイムの影響でこの写真を撮ったのは19時過ぎでしたが、まだ太陽が出ています。素晴らしい光景でした。

Next '23期間中、Google Cloud Japan Teamの皆様が独自に以下のイベントを現地で開催してくださり、それぞれ参加させて頂きました。
- Japan Welcome Lounge(Next '23開催前日に催された日本からの参加者のウェルカムアワー)
- カジュアルディナー @ NEXT(日本から参加した同じ業界の皆様との懇親会)
- Google Cloud 個別ミーティング(現地Google Cloud TeamのProduct Managerとのミーティング)
- Japan Session & Reception(Next '23のハイライトを日本語で伝えるRecap的イベント&Googleグッズが当たるクイズ大会もあった懇親会)
これらのイベントにより、今回の発表内容の理解がさらに深められ、日本から参加した他社の皆様と交流できました。(Google Cloud Japan Teamの皆様にはこの場をお借りして改めて御礼申し上げます)
おわりに
Google Cloud Next '23で紹介されたトピックのうち、BigQuery data clean roomsをいち早く紹介させていただきました。(BigQuery関連はこの他にBigQuery Studio、Duet AI in BigQuery…といったリリースが多数発表されましたが、なくなく割愛します…)
弊社では社外にデータ共有する要件の案件が多くあるため、今回の機能を用いたシステムの導入を検討する予定です。
さらに、Google Cloud Next '23に現地参加したので写真と共にレポートさせていただきました。
今回の現地参加は、Googleのホームであるアメリカで日進月歩的に進化するクラウド技術の最先端にいち早く触れられたので、エンジニアにおいてとても貴重な機会でした。
ちなみに、今回の現地参加に関わる渡航費・宿泊費などは全て会社に負担していただきました。(貴重な機会をいただけて本当に感謝です)
We are hiring
このようにTVerでは、テックカンファレンスへの参加などを通して最新技術のキャッチアップやエンジニアの成長に積極的に投資しています。引き続き、エンジニアリングでTVerの未来を一緒に作っていく仲間も募集していますので、ご興味のある方は以下のリンクからぜひご応募ください!