日々、データ分析をしている森藤です。遅くなってしまいすみません。本記事は TVer アドベントカレンダー 17日目の記事です。 (10日の記事も今度書きます)
TVer のデータを分析の中で大きな割合を占めるものにユーザジャーニーの分析や外部からの流入の分析があります。 これらはどちらも URL の解析が必要になるのですが、 URL はだいたいにおいて Google Analytics の utm パラメタや hash の値が乗っており、 Facebook などは fbclid みたいなのが乗ったりと、これらを削除する作業が必要になります。
具体的には内部の回遊としては、
https://tver.jp/episodes/XXXXXX?utm_campaign=C1&utm_medium=M2&utm_source=S3#V1
などのログがあったり、
https://example.jp:8080/dir1/dir2/index.hml?param1=val1¶m2=val2#hash_value
など外部からの流入があります。
これを BigQuery でパースする際、 BigQuery にも プリイン関数 があるのですが、いまいちリッチではなく、 HOST くらいしかないのです・・・
他にもコミュニティベースの URL_PARSE もあるのですがこちらも、いまいち使い勝手が良くないんですよね
SELECT bqutil.fn.url_parse(url, "QUERY") AS query, FROM UNNEST([ url ]) AS url
僕は「クエリパラメタ」も欲しいんです!
というか JavaScript の new URL() で手に入るオブジェクトくらい全部が欲しいのです!
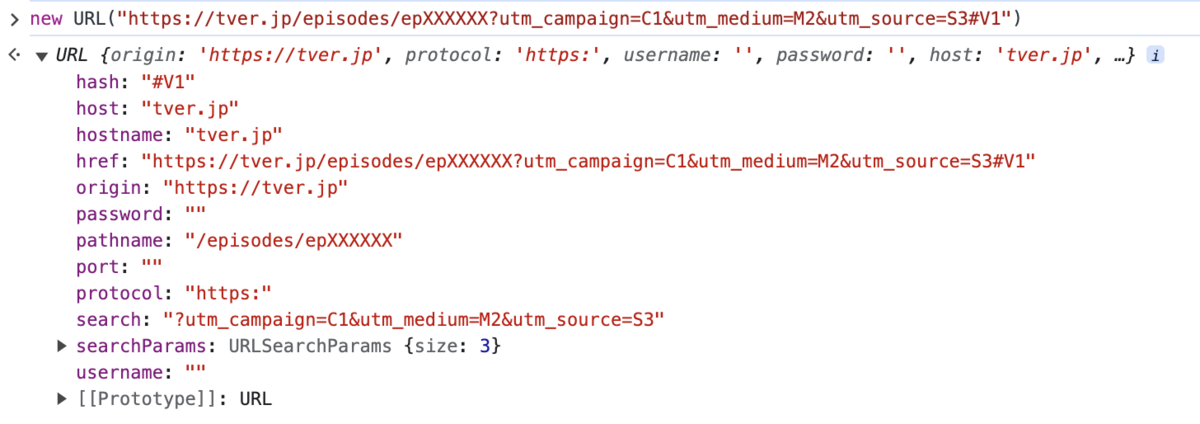
顧客が本当にほしかったもの
理想的にはこちらがほしいです
SELECT url, URL_PARSE(url).protocol, URL_PARSE(url).host, URL_PARSE(url).port, URL_PARSE(url).pathname, URL_PARSE(url).search, FROM UNNEST([ url ]) AS url
まとめ
これを使うと MDN と同じように URL の好きなところを切り出したり取り出すことができます。 searchParam もとれますので、
(SELECT param.value FROM UNNEST(URL_PARSE(url).searchParam) AS param WHERE param.key = "utm_source")
として取り出したりもできます! もちろん、コミュニティ UDF を使っても取り出せますよ! get_value
bqutil.fn.get_value("utm_source", URL_PARSE(url).searchParam)
URL の処理を楽しんでやっていきましょう!
実際のクエリ
作成したクエリ
以下のようなクエリを作成しました。コミュニティに投げ込みます。 ちょっと正規表現が鼻につく感じは自覚しているのですが、テストケースは全部通っています
CREATE TEMP FUNCTION url_parse(url STRING) AS ( STRUCT( REGEXP_EXTRACT(url, r"^([^:]+:)") AS protocol, IF( REGEXP_CONTAINS(url, r"^[^:]+://[^@/:]+:[^@/]+@"), REGEXP_EXTRACT(url, r"^[^:]+://([^@/:]+):[^@/]+@"), NULL ) AS username, IF( REGEXP_CONTAINS(url, r"^[^:]+://[^@/:]+:[^@/]+@"), REGEXP_EXTRACT(url, r"^[^:]+://[^@/:]+:([^@/]+)@"), NULL ) AS password, CONCAT( IF( REGEXP_CONTAINS(url, r"^[^:]+://[^@/:]+:[^@/]+@"), REGEXP_EXTRACT(url, r"^[^:]+://[^@/:]+:[^@/]+@([^:/?#]+)"), REGEXP_EXTRACT(url, r"^[^:]+://([^:/?#]+)") ), IFNULL(IF( REGEXP_CONTAINS(url, r"^[^:]+://[^@/:]+:[^@/]+@"), REGEXP_EXTRACT(url, r"^[^:]+://[^@/:]+:[^@/]+@[^/?#]+(:\d+)"), REGEXP_EXTRACT(url, r"^[^:]+://[^/?#]+(:\d+)") ), "") ) AS host, IF( REGEXP_CONTAINS(url, r"^[^:]+://[^@/:]+:[^@/]+@"), REGEXP_EXTRACT(url, r"^[^:]+://[^@/:]+:[^@/]+@([^:/?#]+)"), REGEXP_EXTRACT(url, r"^[^:]+://([^:/?#]+)") ) AS hostname, IF( REGEXP_CONTAINS(url, r"^[^:]+://[^@/:]+:[^@/]+@"), REGEXP_EXTRACT(url, r"^[^:]+://[^@/:]+:[^@/]+@[^/?#]+:(\d+)"), REGEXP_EXTRACT(url, r"^[^:]+://[^/?#]+:(\d+)") ) AS port, url AS href, REGEXP_EXTRACT(REGEXP_REPLACE(url, r"^[^:]+://([^@/:]+:[^@/]+@)", REGEXP_EXTRACT(url, r"^[^:]+://")), r"^([^:]+://[^/?#]+)") AS origin, IFNULL(NULLIF(REGEXP_EXTRACT(url, r"^[^:]+://[^/]+(/[^?#]*)"), ""), "/") AS pathname, REGEXP_EXTRACT(url, r"[^?#]\?([^#]+)") AS search, (SELECT ARRAY_AGG(STRUCT( SPLIT(param, "=")[SAFE_OFFSET(0)] AS key, SPLIT(param, "=")[SAFE_OFFSET(1)] AS value )) FROM UNNEST(SPLIT(REGEXP_EXTRACT(url, r"[^?#]\?([^#]+)"), "&")) AS param) AS searchParam, REGEXP_EXTRACT(url, r"[^?#]\#(.+)") AS hashval ) );
テストケースも合わせて掲載しておきます
WITH test_data AS ( SELECT FORMAT("%s//%s%s%s%s%s%s", protocol, basicauth, hostname, port, pathname, search, hashval) AS url, protocol, basicauth, hostname, port, pathname, search, hashval FROM UNNEST(["tverapp:", "https:"]) AS protocol INNER JOIN UNNEST(["", "hoge:fuga@"]) AS basicauth ON TRUE INNER JOIN UNNEST(["example.com"]) AS hostname ON TRUE INNER JOIN UNNEST(["", ":8080"]) AS port ON TRUE INNER JOIN UNNEST(["", "/", "/index.html", "/dir1", "/dir1/", "/dir1/index.html"]) AS pathname ON TRUE INNER JOIN UNNEST(["", "?param1=val1"]) AS search ON TRUE INNER JOIN UNNEST(["", "#hash"]) AS hashval ON TRUE )